一 : MySQL实现批量插入测试数据
方法: 存储过程实现
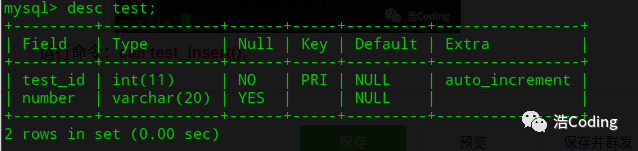
在这之前先查看一下表结构 desc test; 方便写插入语句:
存储过程:
DROP PROCEDURE IF EXISTS test_insert;--如果存在此存储过程则删掉
DELIMITER $
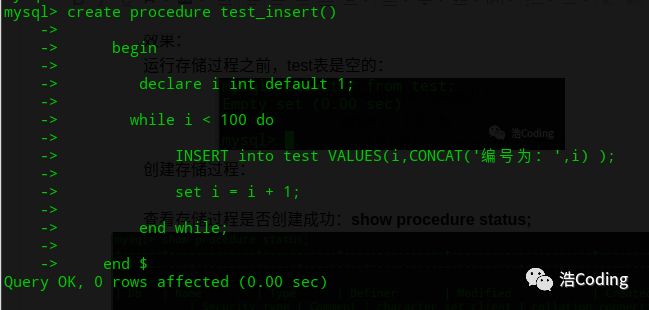
create procedure test_insert()
begin
declare i int default 1;
while i < 100 do
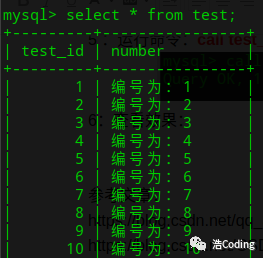
INSERT into test VALUES(i,CONCAT('编号为:',i) );
set i = i + 1;
end while;
end $注:DELIMITER这个命令的用途,在MySQL中每行命令都是用“;”结尾,回车后自动执行,在存储过程中“;”往往不代表指令结束,马上运行,而DELIMITER原本就是“;”的意思,因此用这个命令转换一下“;”为$,
这样只有收到 $才认为指令结束可以执行。
1 : 记得将语句的结束符号恢复为分号:delimiter ;
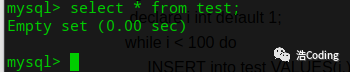
2 :运行存储过程之前,test表是空的:
3 :创建存储过程:
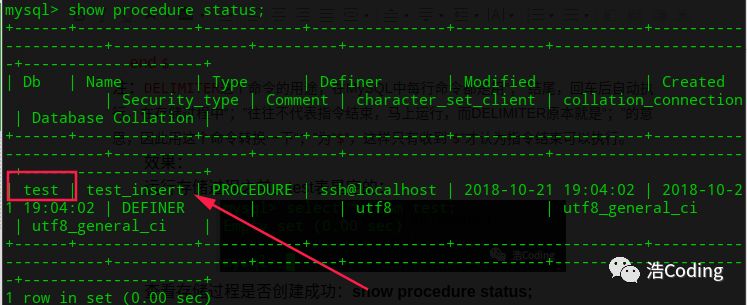
4 :查看存储过程是否创建成功:show procedure status;
5 :运行命令:call test_insert();

6:查看效果:
二 : MySQL实现分页查询
方法一:limit
就 两条语句:
select count(*) from table : 查询得到记录总条数,便于决定分页。
select * from table limit pageNo,rowsCount : 查询从第pageNo条开始的rowsCount条数据。
这是最常见MYSQL最基本的分页方式,查询前10条数据,倒序就加上desc:
select * from test order by test_id limit 0, 10;
在中小数据量的情况下,这样的SQL足够用了,唯一需要注意的问题就是确保使用了索引。随着数据量的增加,页数会越来越多,查看后几页的SQL就可能类似:
select * from content order by id limit 1000000, 10;
一言以蔽之,就是越往后分页,LIMIT语句的偏移量就会越大,速度也会明显变慢。 此时,我们可以通过另一种式:子查询的分页方式来提高分页效率,从第10条开始,查询10条,SQL语句如下:
select * from test where test_id >=
(select test_id from test limit 10, 1) limit 10;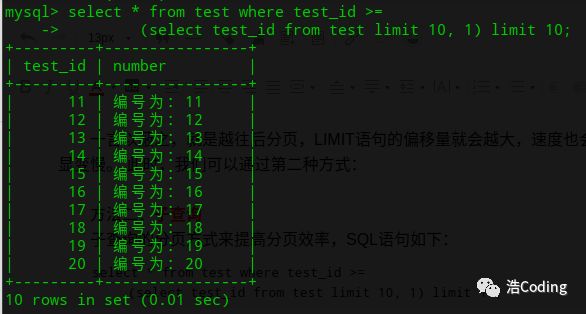
为什么会这样呢?因为子查询是在索引上完成的,而普通的查询时在数据文件上完成的,通常来说,索引文件要比数据文件小得多,所以操作起来也会更有效率。
方法二:使用between and
还有另一种就是 between and,这个方法缺点是id必须连续的 :
select * from test where test_id between 20 and 30; 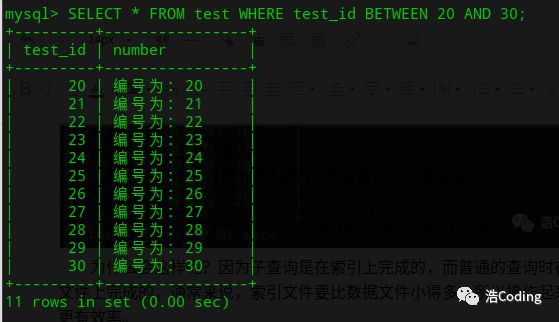
如果需要查询 id 不是连续的一段,最佳的方法就是先找出 id ,然后用 in 查询:
select * from test where test_id in (23,45,79);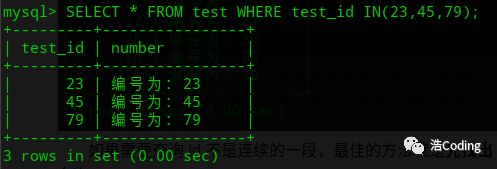
参考文章:
https://blog.csdn.net/qq_34523482/article/details/77834669
https://blog.csdn.net/CSDN2497242041/article/details/79256063
来源:浩Coding
