Oracle? Database SQL Tuning Guide
Part IV SQL Operators: Access Paths and Joins
--- 8 Optimizer Access Paths
--- 9 Joins
9 Joins
Oracle 数据库为连接行集提供了几种优化。
9.1 关于连接
连接 将来自两个行源(如表或视图)的输出合并起来,并返回一个行源。返回的行源是数据集。
连接的特征是在WHERE (非 ANSI )或 FROM 中多个表的. JOIN ( ANSI ) 子 语。当FROM 子句中存在多个表时, Oracle 数据库将执行 连 接。
连 接条件使用表达式比较两个行源。 连接 条件定义表之间的关系。如果语句未指定 连 接条件,则数据库执行笛卡尔 连 接 (Cartesian join) ,将一个表中的每一行与另一个表中的每一行匹配。
9.1.1 连接 树
通常, 连 接树表示为 倒 树结构。
如下图所示,table1 为左表, table2 为右表。优化器从左到右处理连接。例如,如果这个图形描述了一个嵌套循环连接 (nested loops join,) ,那么table1 是外部循环 (outer loop) ,table2 是内部循环 (inner loop) 。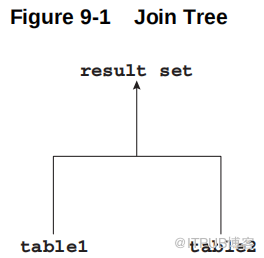
联接的输入可以是前一个联接的结果集。如果联接树的每个内部节点的右子节点是一个表,那么该树就是一个左深联接树,如下面的示例所示。大多数连接树都是左深连接。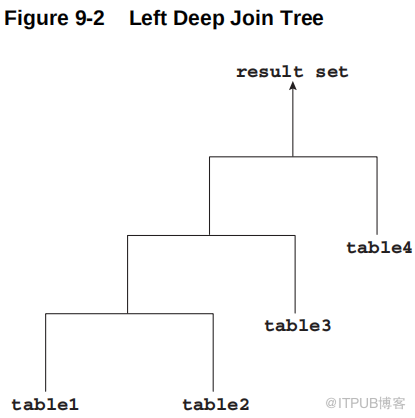
如果联接树的每个内部节点的左子节点是一个表,则该树称为右深联接树,如下图所示。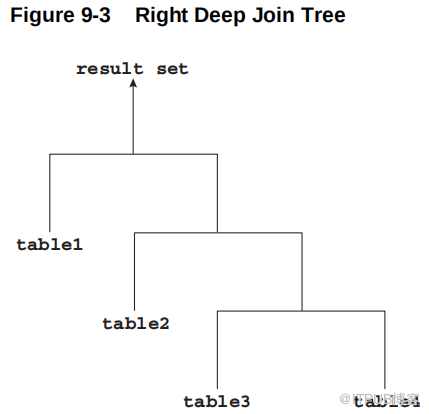
如果联接树的内部节点的左子节点或右子节点可以是联接节点,则该树称为浓密联接树。在下面的示例中,table4 是一个联接节点的右子节点, table1 是一个联接节点的左子节点, table2 是一个联接节点的左子节点。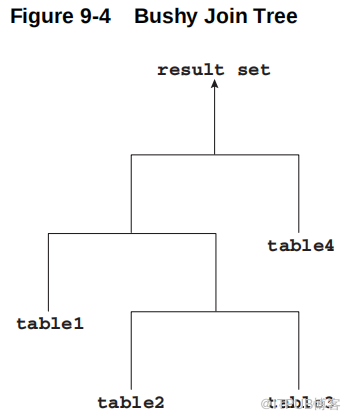
在另一个变体中,联接的两个输入都是前一个联接的结果 。
9.1.2 优化器如何执行连接语句
数据库连接行源对。当FROM 子句中存在多个表时,优化器必须确定每对表中哪一个联接操作最有效。
优化器必须做出下表所示的相关决策。
Table 9-1 Join Operations
操作:访问路径
解释:对于简单语句,优化器必须选择一个访问路径来从连接语句中的每个表检索数据。例如,优化器可能会在全表扫描或索引扫描之间进行选择。
操作:连接方式
解释:要联接每一对行源,Oracle 数据库必须决定如何联接。“ how ”是连接方法。可能的连接方法有嵌套循环 (nested loop) 、排序合并 (sort merge) 和哈希连接 ( hash joins) 。笛卡尔连接 (Cartesian join) 需要前面的连接方法之一。每种连接方法都有特定的情况,在这些情况下,它比其他方法更适合。
操作:连接类型
解释:联接条件确定联接类型。例如,内部联接仅检索与联接条件匹配的行。外部联接检索与联接条件不匹配的行。
操作:连接顺序
解释:要执行连接两个以上表的语句,Oracle 数据库先连接两个表,然后将产生的行源连接到下一个表。这个过程将一直持续下去,直到所有表都连接到结果中为止。例如,数据库连接两个表,然后将结果连接到第三个表,然后将这个结果连接到第四个表,依此类推。
9.1.3 优化器如何为连接选择执行计划
在确定连接顺序和方法时,优化器的目标是尽早减少行数,以便在整个SQL 语句执行过程中执行更少的工作。
优化器根据可能的连接顺序、连接方法和可用的访问路径生成一组执行计划。然后,优化器估计每个计划的成本,并选择成本最低的一个。在选择执行计划时,优化器会考虑以下因素:
? 优化器首先确定连接两个或多个表是否会导致一个至多包含一行的行源。
优化器根据表上惟一的主键约束来识别这种情况。如果存在这种情况,那么优化器将首先按照连接顺序放置这些表。然后优化器优化其余表集的连接。
? 对于带有外部连接条件的连接语句,带有外部连接操作符的表通常按照连接顺序位于条件中的另一个表之后。
通常,优化器不会考虑违反此准则的连接顺序,尽管在某些情况下,优化器会覆盖此顺序条件。类似地,当一个子查询被转换成反连接或半连接时,子查询中的表必须位于它们所连接或关联的外部查询块中的那些表之后。然而, 哈希 反连接和半连接能够在某些情况下覆盖这个排序条件。
优化器通过计算估计的I/Os 和 CPU 来估计查询计划的成本。这些 I/Os 具有与之相关的特定成本 : 单个块 I/O 的成本,以及多个块 I/Os 的成本。另外,不同的函数和表达式都有与之相关的 CPU 成本。优化器使用这些指标确定查询计划的总成本。这些指标可能会受到许多初始化参数和编译时的会话设置的影响,比如 DB_FILE_MULTI_BLOCK_READ_COUNT 设置、系统统计信息等等。
例如,优化估计成本的方式如下:
? 嵌套循环联接的成本取决于将外部表的每个选定行及其内部表的每个匹配行读入内存的成本。优化器使用数据字典中的统计信息来估计这些成本。
? 排序合并连接的成本很大程度上取决于将所有源读入内存并进行排序的成本。
? 哈希连接 的成本很大程度上取决于在连接的一个输入端构建 哈希 表,并使用连接另一端的行探测它的成本。
例9-1 估计连接顺序和方法的成本
从概念上讲,优化器构造了一个连接顺序和方法的矩阵,以及与每个连接顺序和方法相关的成本。例如,优化器必须确定如何在查询中最好地联接date_dim 和 lineorder 表。下表显示了方法和订单的可能变化,以及每种方法和订单的成本。在本例中,嵌套循环联接的顺序是 date_dim, lineorder 的成本最低。
表9-2 date_dim 和 lineorder 表连接的示例成本
9.2 连接 方式
连接 方式 是连接两个行源的机制。
根据统计数据,优化器选择估计成本最低的方法。如图9-5 所示,每个连接方法有两个子方法:驱动(也称为外部)行源和 被 驱动(也称为内部)行源。
9.2.1 嵌套循环连接 (Nested Loops Joins)
嵌套循环将外部数据集连接到内部数据集。
对于与单表谓词匹配的外部数据集中的每一行,数据库检索内部数据集中满足连接谓词的所有行。如果索引可用,那么数据库可以使用它来访问rowid 的内部数据集。
9.2.1.1 优化器 何时 考虑嵌套循环连接
当数据库连接小的数据子集时,嵌套循环连接非常有用; 当数据库连接大的数据集时,优化器模式设置为 FIRST_ROWS ,或者连接条件是访问内部表的有效方法时,嵌套循环连接非常有用。
注意:
连接所期望的行数是驱动优化器决策的因素,而不是底层表的大小。例如,一个查询可能连接两个各有10 亿行的表,但是由于过滤器的原因,优化器期望每个数据集有 5 行。
一般来说,嵌套循环联接在具有联接条件索引的小表上最有效。如果行源只有一行,如对主键值进行相等查找(例如,employee_id=101 ),则联接是一个简单的查找。优化器总是试图将最小的行源放在第一位,使其成为驱动表。
优化器决定使用嵌套循环的因素有很多。例如,数据库可以在一个批处理中从外部行源读取几行。根据检索到的行数,优化器可以选择到内部行源的嵌套循环或哈希联接。例如,如果查询将部门联接到驱动表employees ,并且谓词在 employees.last_name 中指定了一个值,则数据库可能会读取 last_name 索引中的足够条目,以确定是否传递了内部阈值。如果阈值未通过,优化器将选择到部门的嵌套循环联接,如果阈值通过,则数据库将执行哈希联接,这意味着读取其余员工,将其哈希到内存中,然后加入到部门。
如果内部循环的访问路径不依赖于外部循环,则结果可以是笛卡尔积:对于外部循环的每次迭代,内部循环生成相同的行集。若要避免此问题,请使用其他联接方法联接两个独立的行源。
9.2.1.2 嵌套循环联接 工作原理
从概念上讲,嵌套循环相当于两个嵌套的for 循环。
例如,如果一个查询连接了员工 表 和部门 表 ,那么伪代码中的嵌套循环可能是:
内部循环对外部循环的每一行执行。employees 表是 “ 外部 ” 数据集,因为它位于外部 for 循环中。外部表有时称为驱动表。 departments 表是 “ 内部 ” 数据集,因为它位于内部的 for 循环中。
嵌套循环连接涉及以下基本步骤:
1. 优化器确定驱动行源并将其指定为外部循环。
外层循环产生一组用于驱动连接条件的行。行源可以是使用索引扫描、全表扫描或任何其他生成行的操作访问的表。
内部循环的迭代次数取决于外部循环中检索到的行数。例如,如果从外部表检索10 行,那么数据库必须在内部表中执行 10 次查找。如果从外部表检索到 10,000,000 行,那么数据库必须在内部表中执行 10,000,000 个查找。
- 优化器将另一个行源指定为内部循环。
外部循环出现在执行计划的内部循环之前,具体如下:
NESTED LOOPS
outer_loop
inner_loop
3. 对于客户端的每次取数请求,基本过程如下:
a 、从外部行源获取行
b 、探测内部行源以查找与谓词条件匹配的行
c 、重复前面的步骤,直到获取请求获得所有行
有时数据库会对rowid 进行排序,以获得更有效的缓冲区访问模式。
9.2.1.3 嵌套 嵌套循环
嵌套循环的外部循环本身可以是由不同的嵌套循环生成的行源。
数据库可以嵌套两个或更多的外部循环,以便根据需要联接尽可能多的表。每个循环都是一个数据访问方法。下面的模板展示了数据库是如何遍历三个嵌套循环的:
数据库对循环的排序如下:
1. 数据库遍历嵌套循环 1:
嵌套循环1 的输出是一个行源。
2. 数据库遍历嵌套循环 2 ,使用嵌套循环 1 生成的行源作为它的外循环 :
嵌套循环2 的输出是另一个行源。
3. 数据库遍历嵌套循环 3 ,使用嵌套循环 2 生成的行源作为它的外循环 :
例9-2 嵌套嵌套循环联接
假设您按如下方式连接employees 和 departments 表:
SELECT /+ ORDERED USE_NL(d) /
e.last_name , e.first_name , d.department_name
FROM employees e , departments d
WHERE e.department_id = d.department_id
AND e.last_name like 'A%' ;
该计划显示,优化器选择了两个嵌套循环( 步骤 1 和步骤 2) 访问数据 :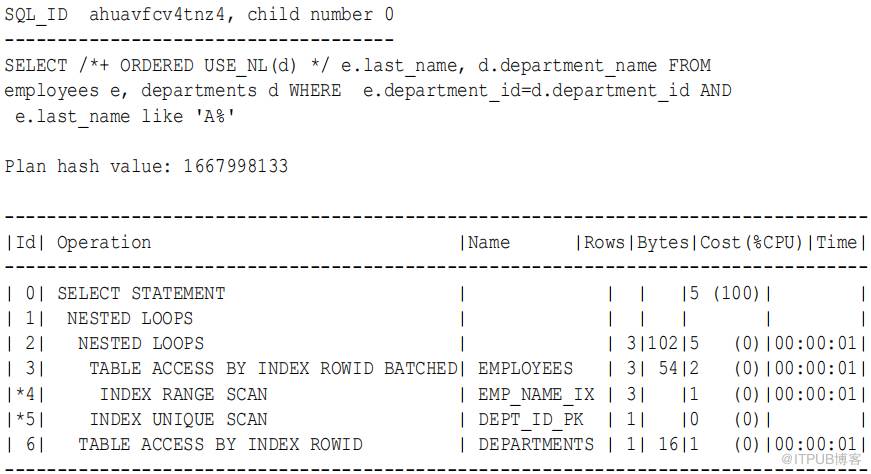

在本例中,基本过程如下:
1. 数据库开始遍历内部嵌套循环(步骤 2 ),如下所示:
a 、 数据库在 emp_name_ix 中搜索 rowids ,查找以 a 开头的所有姓氏(步骤 4 )。
例如:
Abel,employees_rowid
Ande,employees_rowid
Atkinson,employees_rowid
Austin,employees_rowid
b. 使用前一步中的 rowid ,数据库从 employees 表中检索一批行 ( 步骤 3) ,例如 :
Abel,Ellen,80
Abel,John,50
这些行成为最内层嵌套循环的外部行源。
批处理步骤通常是自适应执行计划的一部分。要确定嵌套循环是否优于 哈希连接 ,优化器需要确定从行源返回的许多行。如果返回了太多行,那么优化器将切换到不同的连接方法。
c. 对于外部行源中的每一行,数据库扫描dept_id_pk 索引以获得匹配部门ID 的部门中的 rowid( 步骤 5) , 并将其连接到employees 行。例如:
Abel,Ellen,80,departments_rowid
Ande,Sundar,80,departments_rowid
Atkinson,Mozhe,50,departments_rowid
Austin,David,60,departments_rowid
这些行成为外部嵌套循环的外部行源( 步骤 1) 。
2. 数据库遍历外部嵌套循环,如下所示:
a 、 数据库读取外部行源中的第一行。例如:
Abel,Ellen,80,departments_rowid
b 、 数据库使用 departments rowid 从 departments 检索相应的行(步骤 6 ),然后连接结果以获取请求的值(步骤 1 )。
例如:
Abel,Ellen,80,Sales
c 、 数据库读取外部行源中的下一行,使用 departments rowid 从 departments 检索相应的行(步骤 6 ),并遍历循环,直到检索到所有行。
结果集的格式如下:
Abel,Ellen,80,Sales
Ande,Sundar,80,Sales
Atkinson,Mozhe,50,Shipping
Austin,David,60,IT
9.2.1.4 嵌套循环联接的当前实现
Oracle Database 11g 引入了一种新的嵌套循环实现,它减少了物理 I/O 的总体延迟。
当索引或表块不在缓冲区缓存中并且需要处理连接时,需要物理I/O 。数据库可以批处理多个物理 I/O 请求,并使用向量 I/O (数组)而不是一次处理一个。数据库向执行读取的操作系统发送一个 rowid 数组。
作为新实现的一部分,两个嵌套循环连接行源可能出现在执行计划中,而在以前的版本中只有一个会出现在执行计划中。在这种情况下,Oracle 数据库会分配一个嵌套循环连接行源,将连接外部表中的值与内部的索引连接起来。第二行源被分配来联接第一个联接的结果,其中包括存储在索引中的 rowid ,表位于联接的内侧。
考虑“ 嵌套循环联接的原始实现 ” 中的查询。在当前实现中,此查询的执行计划可能如下: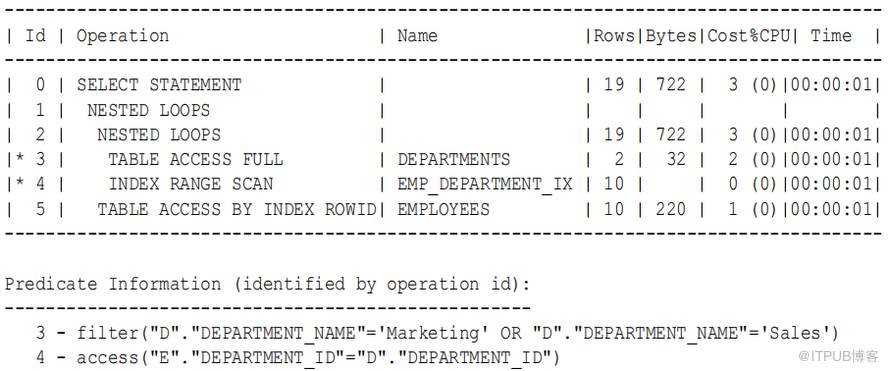
在本例中,hr.departments 表中的行构成内部嵌套循环(步骤 2 )的外部行源(步骤 3 )。索引 emp_department_ix 是内部嵌套循环的内部行源(步骤 4 )。内部嵌套循环的结果构成外部嵌套循环(第 1 行)的外部行源(第 2 行)。 employees 表是外部嵌套循环的外部行源(第 5 行)。
对于每个fetch 请求,基本过程如下:
1. 数据库遍历内部嵌套循环(步骤 2 )以获得获取中请求的行:
a 、 数据库读取第一行部门以获取名为 Marketing 或 Sales 的部门的部门 ID (步骤 3 )。例如:
Marketing,20
此行集合是外部循环。数据库将数据缓存在PGA 中。
b 、 数据库扫描 emp_department_ix ( employees 表上的一个索引),以查找与此 department ID 相对应的 employees 行 ID (步骤 4 ),然后 连接 结果 集 (步骤2 )。
结果集的格式如下:
Marketing,20,employees_rowid
Marketing,20,employees_rowid
Marketing,20,employees_rowid
c 、 数据库读取下一行部门,扫描 emp_department_ix 以找到与此部门 ID 相对应的员工行 ID ,然后遍历循环,直到满足客户端请求。
在本例中,数据库只在外部循环中迭代两次,因为只有来自部门的两行满足谓词过滤器。
从概念上讲,结果集具有以下形式:
Marketing,20,employees_rowid
Marketing,20,employees_rowid
Marketing,20,employees_rowid
...
Sales,80,employees_rowid
Sales,80,employees_rowid
Sales,80,employees_rowid
...
这些行成为外部嵌套循环的外部行源(步骤1 )。
此行集缓存在PGA 中。
2. 数据库将上一步获得的 rowid 组织起来,以便在缓存中更有效地访问它们。
3. 数据库开始遍历外部嵌套循环,如下所示:
a 、 数据库从上一步获得的行集合中检索第一行,如下例所示:
Marketing,20,employees_rowid
b 、 使用 rowid ,数据库从 employees 检索一行以获取请求的值(步骤 1 ),如下例所示:
Michael,Hartstein,13000,Marketing
c 、 数据库从行集中检索下一行,使用 rowid 探测匹配行的雇员,并在循环中迭代,直到检索到所有行。
结果集的格式如下:
Michael,Hartstein,13000,Marketing
Pat,Fay,6000,Marketing
John,Russell,14000,Sales
Karen,Partners,13500,Sales
Alberto,Errazuriz,12000,Sales
...
在某些情况下,未分配第二个联接行源,执行计划与Oracle Database 11g 之前的执行计划相同。以下列表描述了这些情况:
? 索引中存在连接内侧所需的所有列,不需要表访问。在这种情况下, Oracle 数据库只分配一个连接行源。
? 返回的行的顺序可能与 Oracle Database 12c 之前版本中返回的顺序不同。因此,当 Oracle Database 尝试保留行的特定顺序(例如,为了消除按排序的顺序的需要)时, Oracle Database 可能会使用嵌套循环联接的原始实现。
?OPTIMIZER_FEATURES_ENABLE 初始化 参数设置为Oracle Database 11g 之前的版本。在这种情况下, Oracle Database 使用原始实现进行嵌套循环联接。
9.2.1.5 嵌套循环联接的原始实现
在当前版本中,嵌套循环的新实现和原始实现都是可能的。
对于原始实现的示例,请考虑
hr.employees 和 hr.departments 表:
SELECT e.first_name , e.last_name , e.salary , d.department_name
FROM hr.employees e , hr.departments d
WHERE d.department_name IN ( 'Marketing' , 'Sales' )
AND e.department_id = d.department_id ;
在Oracle Database 11g 之前的版本中,此查询的执行计划可能如下所示: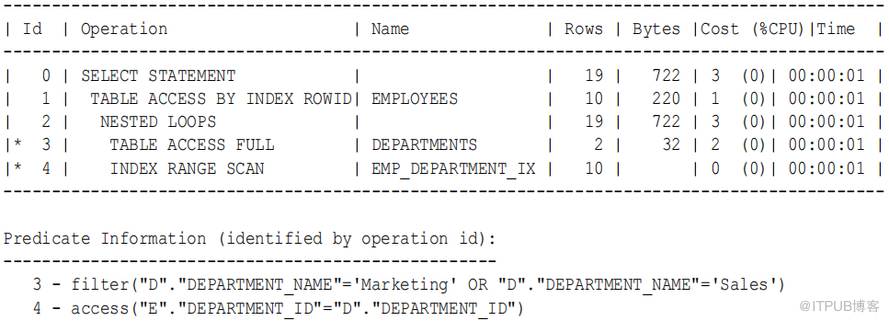
对于每个fetch 请求,基本过程如下:
1. 数据库遍历循环以获取请求的行:
a 、 数据库读取第一行部门以获取名为 Marketing 或 Sales 的部门的部门 ID (步骤 3 )。例如:
Marketing,20
此行集合是外部循环。数据库缓存PGA 中的行。
b 、 数据库扫描 emp_department_ix ( employees.department_id 列上的索引),以查找与此部门 id 相对应的 employees 行 id (步骤 4 ),然后 连接 结果 集 (步骤2 )。
从概念上讲,结果集具有以下形式:
Marketing,20,employees_rowid
Marketing,20,employees_rowid
Marketing,20,employees_rowid
c 、 数据库读取下一行部门,扫描 emp_department_ix 以找到与此部门 ID 对应的员工行 ID ,并在循环中迭代,直到满足客户端请求。
在本例中,数据库只在外部循环中迭代两次,因为只有来自部门的两行满足谓词过滤器。
从概念上讲,结果集具有以下形式:
Marketing,20,employees_rowid
Marketing,20,employees_rowid
Marketing,20,employees_rowid
...
Sales,80,employees_rowid
Sales,80,employees_rowid
Sales,80,employees_rowid
...
2. 根据具体情况,数据库可以组织上一步中获得的缓存的 row id ,以便更有效地访问它们。
3. 对于嵌套循环生成的结果集中的每个 employees rowid ,数据库从 employees 检索一行以获取请求的值(步骤 1 )。
因此,基本过程是读取一个rowid 并检索匹配的 employees 行,读取下一个 rowid 并检索匹配的 employees 行,等等。从概念上讲,结果集具有以下形式:
Michael,Hartstein,13000,Marketing
Pat,Fay,6000,Marketing
John,Russell,14000,Sales
Karen,Partners,13500,Sales
Alberto,Errazuriz,12000,Sales
...
9.2.1.6 嵌套循环 控制
可以添加USE _ NL 提示,指示优化器使用指定表作为内部表,使用嵌套循环联接将每个指定表联接到另一行源。
相关提示USE_NL_WITH_INDEX ( table INDEX )提示指示优化器将指定表连接到另一个具有嵌套循环的行源,使用指定表作为内部表连接。索引是可选的。如果未指定索引,则嵌套循环联接使用至少有一个联接谓词的索引作为索引键。
示例9-3 嵌套循环提示
假设优化器为以下查询选择哈希联接:
SELECT e.last_name , d.department_name
FROM employees e , departments d
WHERE e.department_id = d.department_id ;
执行计划如下:
要使用部门作为内部表强制嵌套循环连接,请添加USE_NL 提示,如下面的查询所示 :
SELECT /+ ORDERED USE_NL(d) /
e.last_name , d.department_name
FROM employees e , departments d
WHERE e.department_id = d.department_id ;
执行计划如下: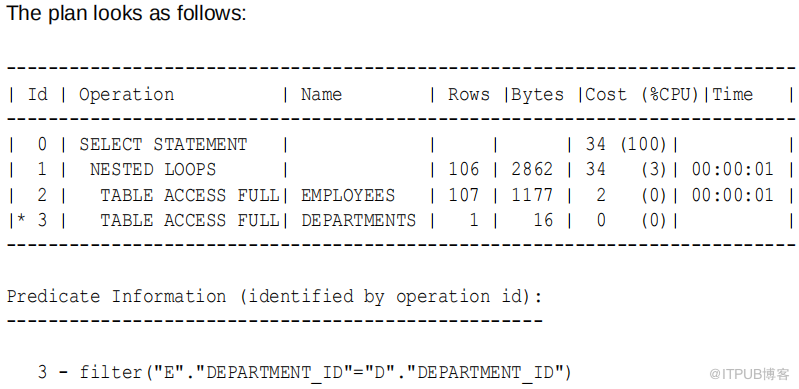
数据库得到的结果集如下:
1. 在嵌套循环中,数据库读取员工 表 以获取员工的姓和部门ID( 步骤 2) ,例如 :
De Haan,90
2. 对于上一步获得的行,数据库扫描 department ,查找与 employees department ID 匹配的部门名称 ( 步骤 3) ,并连接结果 ( 步骤 1) ,例如 :
De Haan,Executive
3. 数据库检索 employee 中的下一行,从 department 中检索匹配的行,然后重复这个过程,直到检索到所有行。结果集的形式如下 :
De Haan,Executive
Kochnar,Executive
Baer,Public Relations
King,Executive
...
9.2.2 Hash Joins
数据库使用哈希联接来联接较大的数据集。
优化器使用两个数据集中较小的一个在内存中的联接键上构建哈希表,使用确定性哈希函数指定哈希表中存储每一行的位置。然后,数据库扫描较大的数据集,探测哈希表以查找满足联接条件的行。
9.2.2.1 优化器 何时会 考虑 哈希连接
通常,当必须连接相对较大的数据量( 或必须连接小表的很大一部分 ) 时,并且连接是等 值 连接 , 优化器会考虑 哈希连接 ,。
当较小的数据集适合于内存时, 哈希连接 的成本效率最高。在这种情况下,成本限制在两个数据集上的一次读取传递。
因为哈希表在PGA 中,所以 Oracle 数据库可以访问行而不需要锁定它们。这种技术通过避免重复锁存和读取数据库缓冲区缓存中的块来减少逻辑 I/O 。
如果数据集在内存中不合适,那么数据库将对行源进行分区,而连接将按分区进行分区。这可能会使用大量的排序区域内存和I/O 到临时表空间。这种方法仍然是最经济有效的,特别是当数据库使用并行查询服务器时。
9.2.2.2 哈希联接的工作原理
哈希算法接受一组输入并应用确定性哈希函数来生成随机哈希值。
在 哈希 联接中,输入值是联接键。输出值是数组(哈希表)中的索引(slots )。
9.2.2.2.1 哈希表
为了演示哈希表,假设数据库对部门 表 和员工 表通过 部门id 关联 进行哈希运算。
前5 行部门 表数据 如下:
SQL > select * from departments where rownum < 6 ;
数据库对表中的每个department_id 应用 哈希 函数,为每个department 生成一个 哈希 值。在这个例子中,哈希表有5 个槽 ( 可以多一点,也可以少一点 ) 。因为 n 是 5 ,所以可能的哈希值的范围是从 1 到 5 。哈希函数可能会为部门 id 生成以下值 :
f(10) = 4
f(20) = 1
f(30) = 4
f(40) = 2
f(50) = 5
注意,哈希函数恰好为部门10 和 30 生成相同的哈希值 4 。这就是所谓的 哈希 冲突。在本例中,数据库使用一个链表将部门10 和部门 30 的记录放在同一个槽中。
从概念上看,哈希表如下:
1 20,Marketing,201,1800
2 40,Human Resources,203,2400
3
4 10,Administration,200,1700 -> 30,Purchasing,114,1700
5 50,Shipping,121,1500
9.2.2.2.2 哈希 连接: 基本步骤
优化器使用较小的数据源在内存中的连接键上构建 哈希 表,然后扫描较大的表来查找连接的行。
基本步骤如下:
1. 数据库对较小的数据集 ( 称为构建表 ) 执行完整扫描,然后对每一行中的连接键应用 哈希 函数,以构建PGA 中的 哈希 表。
在伪代码中,算法可能如下所示:
2. 数据库使用成本最低的访问机制探测第二个数据集 ( 称为探测表 ) 。
通常,数据库会对更小和更大的数据集进行全面扫描。伪代码中的算法可能如下所示:
对于从较大的数据集中检索到的每一行,数据库执行以下操作:
a. 将相同的哈希函数应用于连接列或多个列,以计算哈希表中相关槽的数目。
例如,为了探测部门ID 30 的哈希表,数据库将哈希函数应用到 30 ,它将生成哈希值 4 。
b. 探测哈希表以确定槽中是否存在行。
如果不存在行,则数据库处理较大数据集中的下一行。如果存在行,则数据库继续进行下一步。
c. 检查联接列或多个列是否匹配。如果发生匹配,那么数据库要么报告这些行,要么将它们传递到计划的下一步,然后处理更大数据集中的下一行。
如果哈希表槽中存在多行,则数据库遍历行链表,检查每一行。例如,如果department 30 哈希 到slot 4 ,那么数据库将检查每一行,直到找到 30 为止。
示例9-4 Hash Joins
应用程序查询oe.orders 和 oe.order_items 表, 关联列是 order_i d 。
SELECT o.customer_id , l.unit_price * l.quantity
FROM orders o , order_items l
WHERE l.order_id = o.order_id ;
执行计划如下: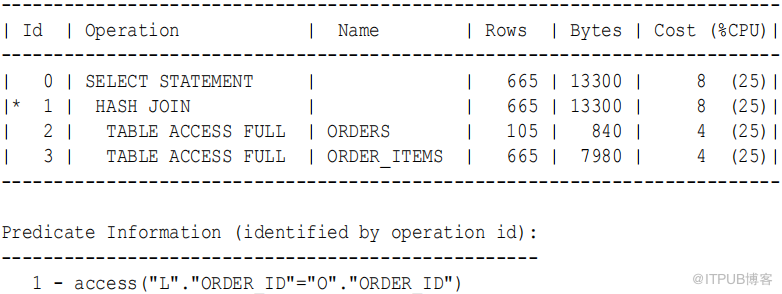
因为orders 表相对于 order_items 表比较小,而 order_items 表要大 6 倍,所以数据库会 哈希 orders 。在 哈希 连接中,构建表的数据集总是首先出现在操作列表中( 步骤 2) 。
9.2.2.3 当哈希表不适合 PGA 时,哈希连接如何工作
当哈希表不能完全适合PGA 时,数据库必须使用另一种技术。在这种情况下,数据库使用一个临时空间来保存哈希表的部分 ( 称为分区 ) ,有时还保存探测哈希表的较大表的部分。
基本流程如下:
1. 数据库对较小的数据集执行完整的扫描,然后在 PGA 和磁盘上构建一个散列桶数组。
当PGA 哈希区填满时,数据库会找到哈希表中最大的分区,并将其写入磁盘上的临时空间。数据库将属于这个磁盘上分区的任何新行存储在磁盘上,以及 PGA 中的所有其他行。因此,哈希表的一部分在内存中,另一部分在磁盘上。
2. 数据库第一次读取其他数据集。对于每一行,数据库执行以下操作 :
a. 将相同的散列函数应用于连接列,以计算相关散列桶的数目。
b. 探测哈希表,以确定内存中的桶中是否存在行。
如果散列值指向内存中的一行,那么数据库将完成连接并返回该行。但是,如果该值指向磁盘上的散列分区,那么数据库将这一行存储在临时表空间中,使用与原始数据集相同的分区方案。
3. 数据库逐个读取每个磁盘上的临时分区
4. 数据库将每个分区行连接到相应的磁盘上临时分区中的行。
9 .2.2.4 Hash Joins 控制
USE_HASH 提示优化器在将两个表连接在一起时使用哈希联接。
9.2.3 排序 合并连接
排序合并联接是嵌套循环联接的变体。
如果联接中的两个数据集尚未排序,则数据库将对它们进行排序。这些是排序连接操作。对于第一个数据集中的每一行,数据库将探测第二个数据集以查找匹配的行并将它们连接起来,它的起始位置基于前一个迭代中进行的匹配。这是合并连接操作。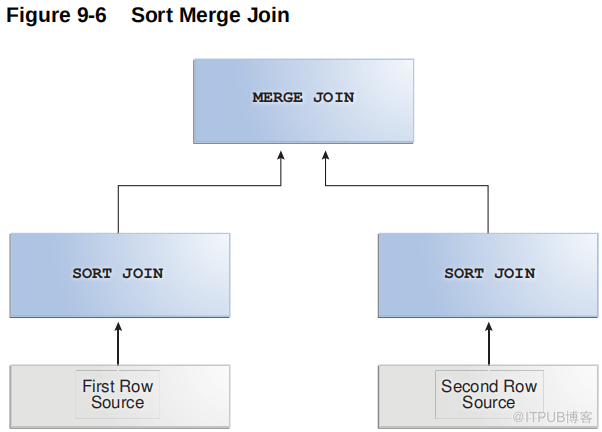
9.2.3.1 优化器 何时 考虑 使用 排序合并连接
哈希 连接需要一个散列表和这个表的一个探测,而排序合并连接需要两个排序。
当下列条件为真时,优化器可以选择排序合并连接而不是散列连接来连接大量数据:
? 两个表之间的联接条件不是 等值 联接,即使用了诸如< 、 <= 、 > 或 >= 这样的不等式条件。
与排序合并不同,散列连接需要一个相等条件。
? 由于其他操作需要排序,优化器发现使用排序合并 成本更低 。
如果存在索引,则数据库可以避免对第一个数据集进行排序。但是,无论索引如何,数据库总是对第二个数据集进行排序。
与嵌套循环连接相比,排序合并具有与散列连接相同的优点: 数据库访问 PGA 中的行,而不是 SGA 中的行,通过避免重复锁存和读取数据库缓冲区缓存中的块,减少了逻辑 I/O 。通常,散列连接比排序合并连接执行得更好,因为排序是昂贵的。但是,与散列连接相比,排序合并连接具有以下优点 :
? 在初始排序之后,合并阶段进行了优化,从而更快地生成输出行。
? 当哈希表不能完全装入内存时,排序合并可能比哈希连接更划算。
内存不足的散列连接需要将散列表和其他数据集复制到磁盘。在这种情况下,数据库可能需要多次从磁盘读取数据。在排序合并中,如果内存不能保存这两个数据集,那么数据库将它们都写入磁盘,但是每个数据集的读取次数不超过一次。
9.2.3.2 排序归并联接的工作原理
与嵌套循环联接一样,sort merge 联接读取两个数据集,但在它们还没有排序时对它们进行排序。
对于第一个数据集中的每一行,数据库在第二个数据集中找到一个起始行,然后读取第二个数据集,直到找到一个不匹配的行。在伪代码中,排序归并的高级算法可能如下所示:
例如,下表显示了两个数据集中的排序值:temp_ds1 和 temp_ds2 。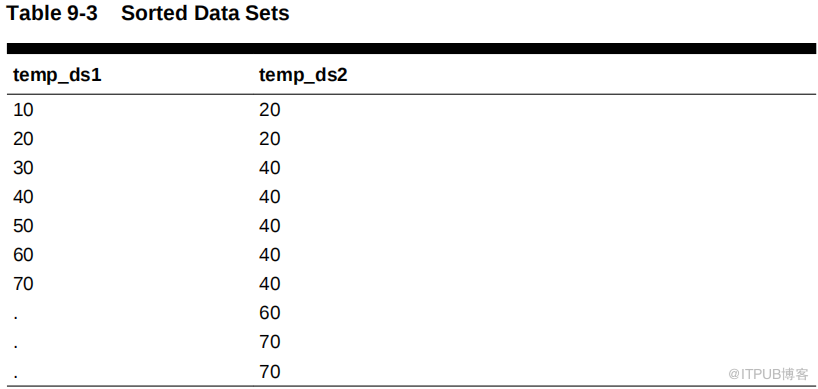
如下表所示,数据库首先读取temp_ds1 中的 10 ,然后读取 temp_ds2 中的第一个值。因为 temp_ds2 中的 20 大于 temp_ds1 中的 10 ,所以数据库停止读取 temp_ds2 。
数据库继续处理temp_ds1 中的下一个值,即 20 。数据库通过 temp_ds2 执行,如下表所示。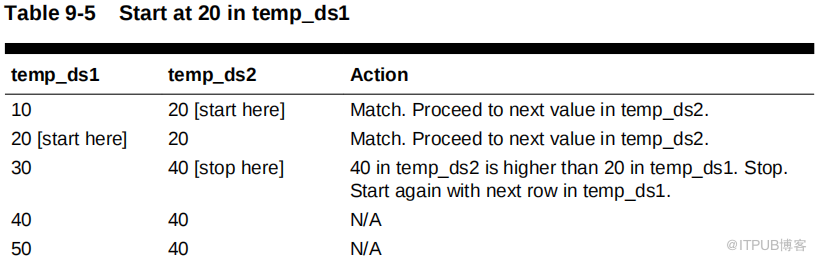
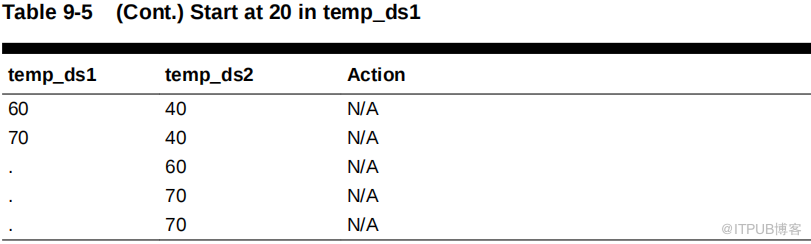
数据库继续到temp_ds1 中的下一行,即 30 。数据库从最后一次匹配的数目 (20) 开始,然后通过 temp_ds2 查找匹配,如下表所示。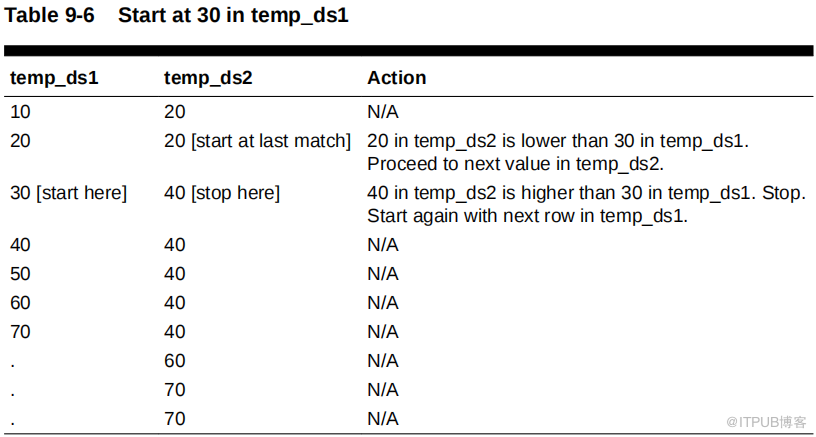
数据库继续到temp_ds1 中的下一行,即 40 。如下表所示,数据库从 temp_ds2 中最后一个匹配项的数量开始,即 20 个,然后通过 temp_ds2 查找匹配项。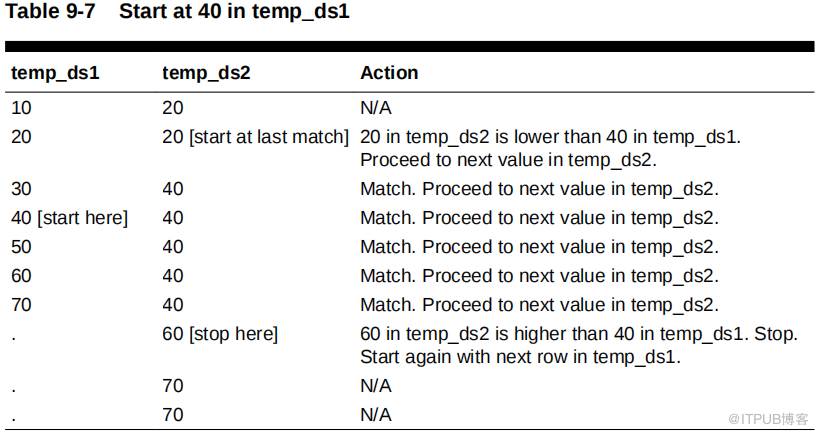
数据库以这种方式继续运行,直到它与temp_ds2 中的最后 70 个匹配为止。这个场景表明,当数据库读取 temp_ds1 时,不需要读取 temp_ds2 中的每一行。与嵌套循环连接相比,这是一个优势。
例9-5 使用索引对合并连接进行排序
下面的查询将连接上的employees 和 departments 表
department_id 列,对 department_id 上的行按如下顺序排序 :
SELECT e.employee_id ,
e.last_name ,
e.first_name ,
e.department_id ,
d.department_name
FROM employees e , departments d
WHERE e.department_id = d.department_id
ORDER BY department_id ;
查询DBMS_XPLAN.DISPLAY_CURSOR显示排序合并联接 执行计划 :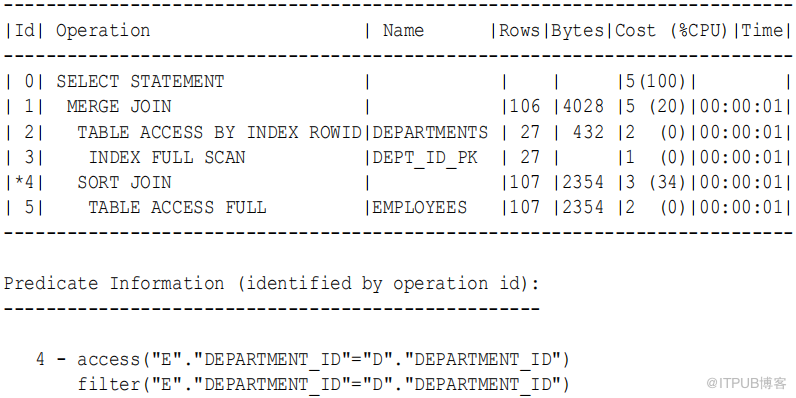
这两个数据集是departments 表和 employees 表。由于索引按部门 id 对 departments 表进行排序,因此数据库可以读取此索引并避免排序(步骤 3 )。数据库只需要对 employees 表进行排序(步骤 4 ),这是 CPU 最密集的操作。
例9-6 没有索引的排序合并连接
在department_id 列上联接 employees 和 departments 表,按如下方式对 department_id 上的行进行排序。在本例中,您指定 NO_INDEX 和 USE_MERGE 来强制优化器选择排序合并 :
SELECT /+ USE_MERGE(d e) NO_INDEX(d) /
e.employee_id ,
e.last_name ,
e.first_name ,
e.department_id ,
d.department_name
FROM employees e , departments d
WHERE e.department_id = d.department_id
ORDER BY department_id ;
查询DBMS_XPLAN.DISPLAY_CURSOR显示排序合并联接 执行计划 :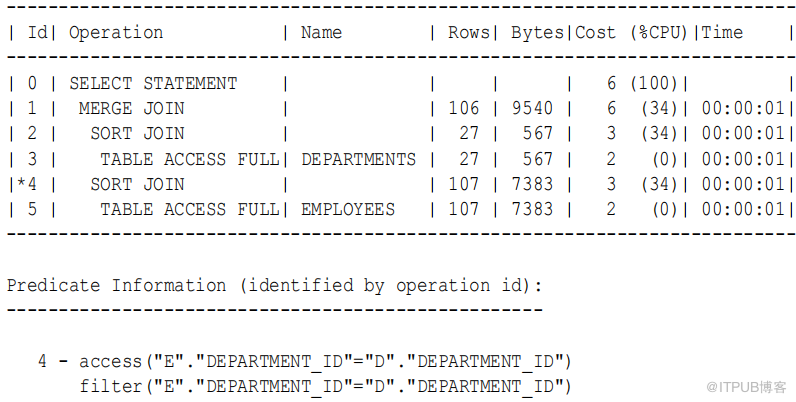
由于忽略了departments.department_id 索引,优化器将执行排序,这将使步骤 2 和步骤 3 的总成本增加 67%( 从 3 增加到 5) 。
9.2.3.3 合并 排序 连接 控制
USE_MERGE 提示指示优化器使用排序合并连接。
在某些情况下,使用USE_MERGE 提示覆盖优化器是有意义的。例如,优化器可以选择对表进行全扫描,并避免在查询中执行排序操作。但是,这样做会增加成本,因为通过索引和单个块读取来访问大表,而不是通过全表扫描进行更快的访问。
9.3 连接类型
连接类型由连接条件的类型决定。
9.3.1 内 连接
内部连接( 有时称为简单连接 ) 是只返回满足连接条件的行的连接。内连接可以是等连接,也可以是非等连接。
9.3.1.1 等值连接
等 值 连接是一个内部连接,其连接条件包含一个等式运算符。
下面的例子是一个等 值 连接,因为连接条件只包含一个等式运算符:
SELECT e.employee_id , e.last_name , d.department_name
FROM employees e , departments d
WHERE e.department_id = d.department_id ;
在前面的查询中,联接条件是e.department_id=d.department_id。如果employees表中的某一行的部门ID与部门表中某一行的值匹配,则数据库返回连接的结果;否则,数据库不会返回结果。
9.3.1.2 非等值连接
非等值连接是一个内部连接,其连接条件包含一个非等值操作符。
下面的查询列出了所有在员工176( 因为他在 2007 年换了工作,所以被列在 job_history 中 ) 在公司工作的员工的雇佣日期 :
SELECT e.employee_id , e.first_name , e.last_name , e.hire_date
FROM employees e , job_history h
WHERE h.employee_id = 176
AND e.hire_date BETWEEN h.start_date AND h.end_date ;
在前面的示例中,连接employees 和 job_history 的条件不包含相等操作符,因此它是一个非相等连接。 非等值连接 的情况比较少见。
请注意,散列连接至少需要部分等 值 连接。下面的SQL 脚本包含一个相等连接条件 (e1.empno = e2.empno) 和一个不相等条件 :
SET AUTOTRACE TRACEONLY EXPLAIN
SELECT *
FROM scott.emp e1
JOIN scott.emp e2
ON ( e1.empno = e2.empno AND e1.hiredate BETWEEN e2.hiredate - 1 AND
e2.hiredate + 1 )
优化器为前面的查询选择一个散列连接,如下面的计划所示: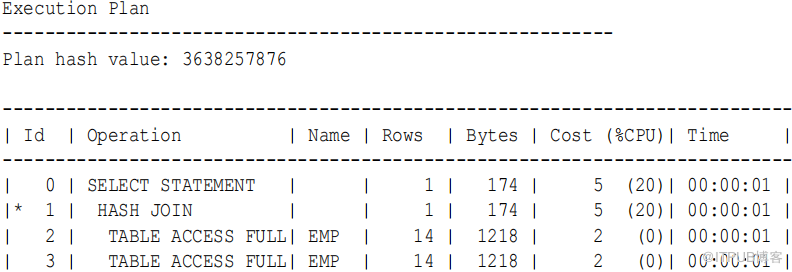
9.3.1.3 Band 带 连接
带连接是一种特殊类型的非 等值 连接,其中一个数据集中的键值必须位于第二个数据集的指定范围(“ 带 ”) 内。同一个表可以同时用作第一个和第二个数据集。
从Oracle 数据库 12c 版本 2(12.2) 开始,数据库可以更有效地评估带连接。该优化避免了对超出定义频带的行进行不必要的扫描。
优化器使用成本评估来选择连接方法( 散列、嵌套循环或排序合并 ) 和并行数据分布方法。在大多数情况下,优化的性能与等效连接相当。
以下示例查询的雇员的工资比每个雇员的工资少100 美元到多 100 美元。因此,带宽为 200 美元。本例假设可以将每个员工的工资与自身进行比较。下面的查询包括部分样本输出 :
SELECT e1.last_name || ' has salary between 100 less and 100 more than ' ||
e2.last_name AS "SALARY COMPARISON"
FROM employees e1 , employees e2
WHERE e1.salary BETWEEN e2.salary - 100 AND e2.salary + 100 ;
例9-7 查询没有带连接优化
在不进行band join 优化的情况下,数据库使用以下查询计划 :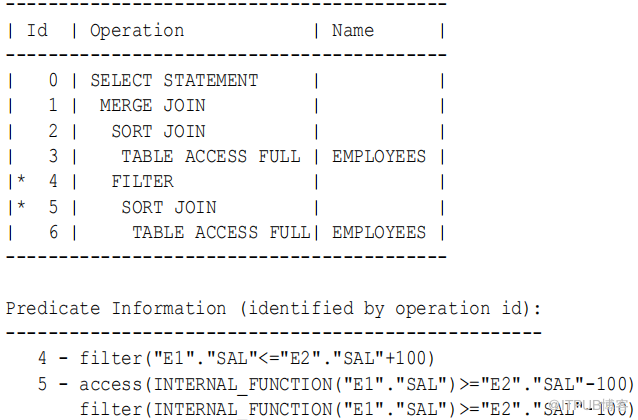
在这个计划中,步骤2 对 e1 行源进行排序,步骤 5 对 e2 行源进行排序。下表说明了排序后的行源。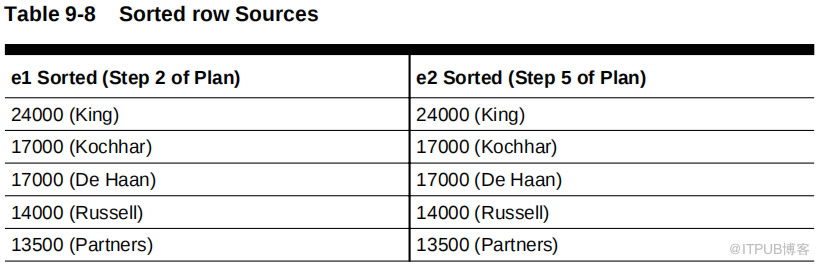
连接首先遍历排序输入(e1 ),它是连接的左分支,对应于计划的步骤 2 。原始查询包含两个谓词:
?e1.sal>=e2.sal–100 ,这是第 5 步过滤器
?e1.sal>=e2.sal+100 ,这是第 4 步过滤器
对于已排序行源e1 的每次迭代,数据库都会迭代行源 e2 ,根据步骤 5 filter e1.sal>=e2.sal–100 检查每一行。如果行通过了步骤 5 筛选器,则数据库将其发送到步骤 4 筛选器,然后继续针对步骤 5 筛选器测试 e2 中的下一行。但是,如果一行未能通过步骤 5 筛选,那么 e2 的扫描将停止,数据库将继续执行 e1 的下一次迭代。
下表显示了e1 的第一次迭代,从数据集 e1 中的 24000 ( King )开始。数据库确定 e2 中的第一行 24000 ( king )通过步骤5 过滤器。然后,数据库将行发送到步骤 4 过滤器 e1.sal<=w2.sal+100 ,后者也通过。数据库将此行发送到合并行源。接下来,数据库检查 17000 ( Kochhar )与步骤 5 过滤器,后者也通过了。但是,该行无法通过步骤 4 筛选器,因此被丢弃。数据库继续根据步骤 5 过滤器测试 17000 ( De Haan )。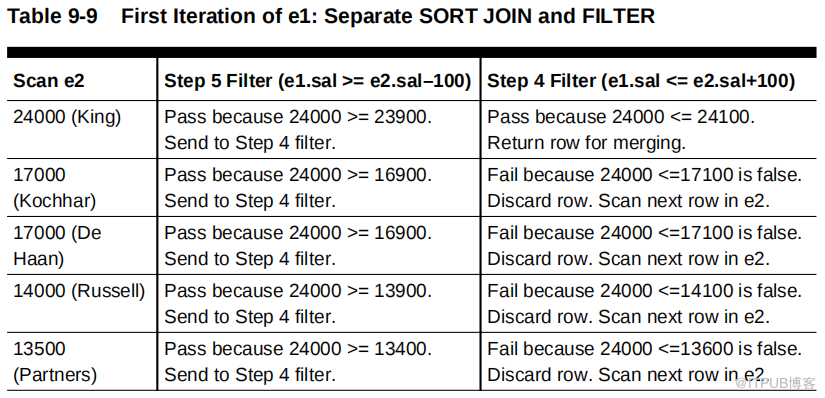
如上表所示,每个e2 行都必须通过步骤 5 筛选,因为 e2 工资是按降序排序的。因此,步骤 5 过滤器总是将行发送到步骤 4 过滤器。因为 e2 工资是按降序排序的,所以步骤 4 过滤器必然会失败,从 17000 开始的每一行( Kochhar )。之所以效率低下,是因为数据库会针对步骤 5 筛选器(必须通过)测试 e2 中的每个后续行,然后针对步骤 4 筛选器(必须失败)进行测试。
示例9-8 带连接优化的查询
从Oracle Database 12c Release 2 ( 12.2 )开始,数据库使用以下计划优化带区联接,该计划没有单独的筛选操作: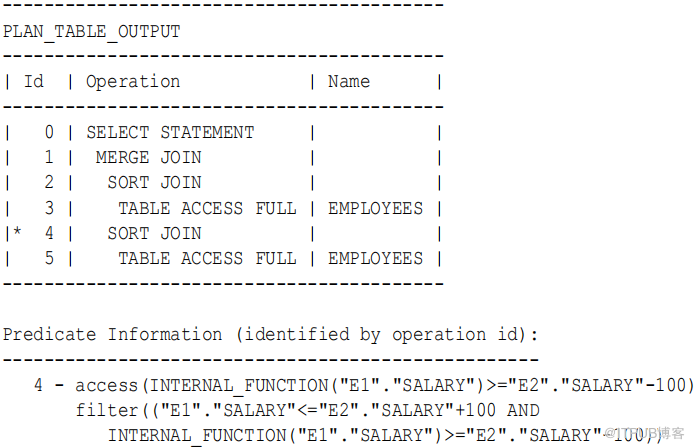
区别在于,步骤4 对两个谓词使用布尔值和逻辑来创建单个筛选器。数据库不对一个筛选器检查一行,然后将其发送到另一个行源以检查第二个筛选器,而是对一个筛选器执行一次检查。如果检查失败,则停止处理。
在本例中,查询从e1 的第一次迭代开始, e1 以 24000 ( King )开头。下图表示范围。 23900 以下和 24100 以上的 e2 值超出范围。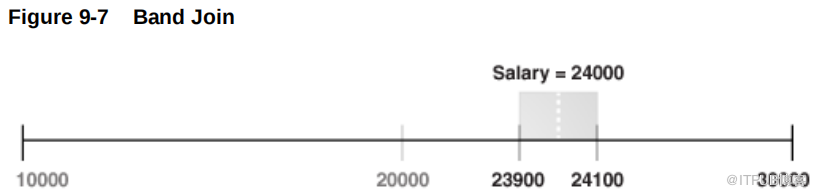
下表显示,数据库根据步骤4 过滤器测试 e2 的第一行,即 24000 ( King )。行通过测试,因此数据库发送要合并的行。 e2 的下一行是 17000 ( Kochhar )。该行超出范围(范围),因此不满足筛选器谓词,因此数据库在此迭代中停止测试 e2 行。数据库停止测试,因为 e2 的降序排序确保 e2 中的所有后续行都无法通过筛选测试。因此,数据库可以进行 e1 的第二次迭代。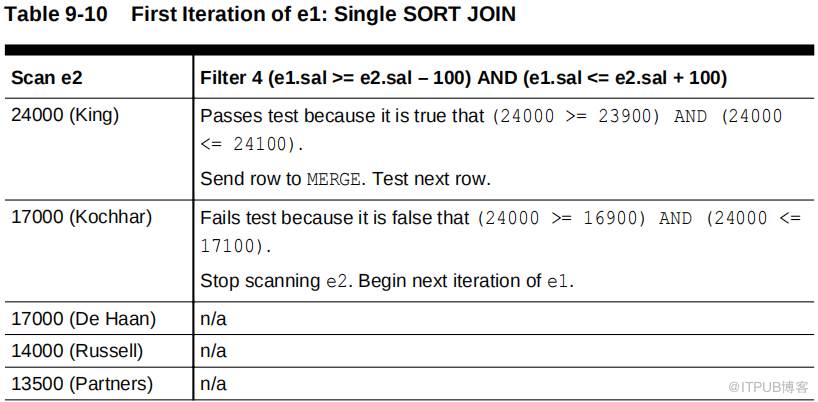
这样,带连接优化消除了不必要的处理。与在未优化的情况下扫描e2 中的每一行不同,数据库只扫描至少两行。
9.3.2 Outer Joins 外连接
外部联接返回满足联接条件的所有行,还返回一个表中没有来自另一个表的行满足联接条件的行。因此,外部联接的结果集是内部联接的超集。
在ANSI 语法中, OUTER JOIN 子句指定一个外部联接。在 FROM 子句中,左表显示在外部联接关键字的左侧,右表显示在这些关键字的右侧。左表也称为外表,右表也称为内表。例如,在下面的语句中 employees 表是左表或外表:
SELECT employee_id , last_name , first_name
FROM employees
LEFT OUTER JOIN departments
ON ( employees.department_id = departments.departments_id );
外连接要求外连接表作为驱动表。在前面的例子中,employees 是 驱动 表,departments 是 被驱动 表。
9.3.2.1 嵌套循环外连接
数据库使用此操作来循环两个表之间的外部连接。外部连接返回外部( 保留的 ) 表行,即使内部 ( 可选 ) 表中没有对应的行。
在一个标准的嵌套循环中,优化器根据成本选择表的顺序,即驱动表和 被 驱动表。但是,在嵌套循环外部连接中,连接条件决定表的顺序。数据库使用外部的行保留表来驱动内部表。
在以下情况下,优化器使用嵌套循环连接来处理外部连接:
? 可以从外部表驱动到内部表。
? 数据量足够低,使嵌套循环方法有效。
对于嵌套循环外部连接的一个示例,您可以将USE_NL 提示添加到示例 9-9 中,以指示优化器使用嵌套循环。例如 :
SELECT /+ USE_NL(c o) /
cust_last_name , SUM ( NVL2 ( o.customer_id , 0 , 1 )) "Count"
FROM customers c , orders o
WHERE c.credit_limit > 1000
AND c.customer_id = o.customer_id (+)
GROUP BY cust_last_name ;
9.3.2.2 散列连接外部连接
当数据量大到足以使散列连接有效时,或者无法从外部表驱动到内部表时,优化器将使用散列连接来处理外部连接。
成本决定了表格的顺序。外部表( 包括保留的行 ) 可以用来构建哈希表,也可以用来探测哈希表。
例9-9 散列连接外部连接
这个示例展示了一个典型的散列连接外部连接查询及其执行计划。在这个例子中,所有信用限额大于1000 的客户都被查询。需要一个外部连接,以便查询捕获没有订单的客户。
? 外部表是customers 。
? 内部表是 orders 。
? 联接保留 customers 数据 ,包括orders 中没有对应行的那些行。
您可以使用不存在的子查询来返回行。但是,由于要查询表中的所有行,所以散列连接的性能更好( 除非不存在的子查询没有嵌套 ) 。
SELECT cust_last_name , SUM ( NVL2 ( o.customer_id , 0 , 1 )) "Count"
FROM customers c , orders o
WHERE c.credit_limit > 1000
AND c.customer_id = o.customer_id (+)
GROUP BY cust_last_name ;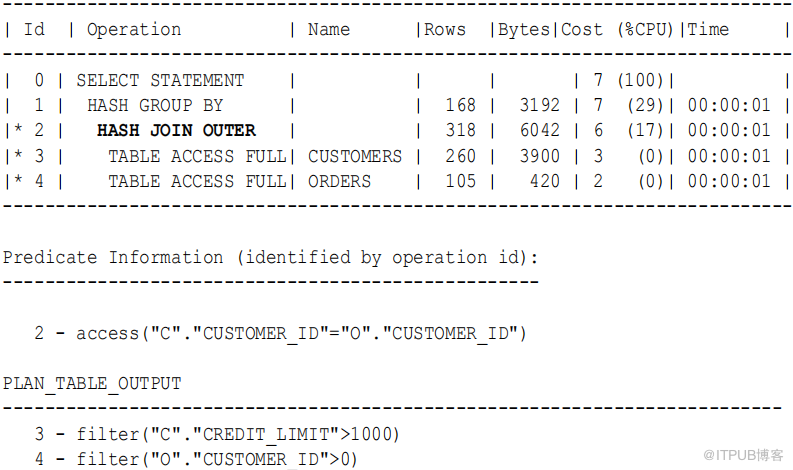
查询查找满足各种条件的客户。当外部联接在内部表中没有找到任何对应的行时,它将为内部表列和外部( 保留的 ) 表行返回 NULL 。此操作查找没有任何订单行的所有客户行。
在这种情况下,外部连接条件如下:
customers.customer_id = orders.customer_id(+)
该条件的组成部分如下:
例9-10 外连接到多表视图
在本例中,外部连接是一个多表视图。优化器不能像普通连接或谓词 推进 那样插入视图,因此它构建视图的整个行集。
SELECT c.cust_last_name , sum ( revenue )
FROM customers c , v_orders o
WHERE c.credit_limit > 2000
AND o.customer_id (+) = c.customer_id
GROUP BY c.cust_last_name ;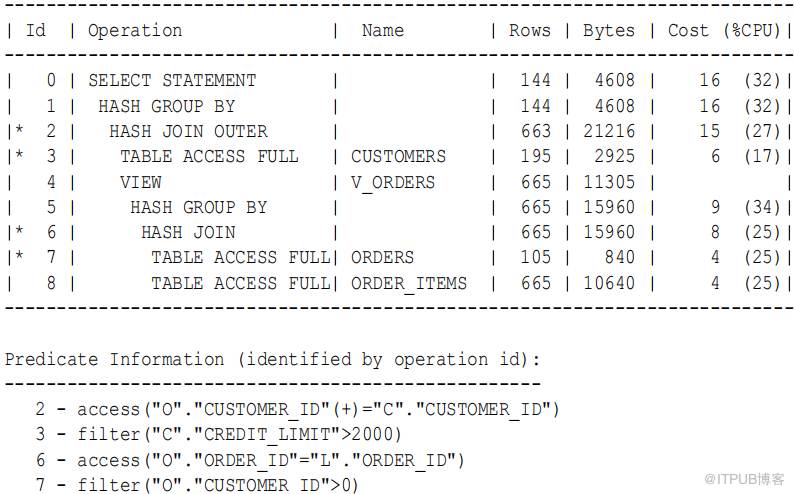
视图定义如下:
CREATE OR REPLACE view v_orders AS
SELECT l.product_id ,
SUM ( l.quantity * unit_price ) revenue ,
o.order_id ,
o.customer_id
FROM orders o , order_items l
WHERE o.order_id = l.order_id
GROUP BY l.product_id , o.order_id , o.customer_id ;
9.3.2.3 排序合并外部连接
当外部联接无法从外部(保留的)表驱动到内部(可选)表时,它不能使用哈希联接或嵌套循环联接。
在这种情况下,它使用sort-merge 外部联接。
优化器在以下情况下对外部联接使用排序合并:
? 嵌套循环连接效率低下。由于数据量的原因,嵌套循环联接可能效率低下。
? 优化器发现在散列连接上使用排序合 成本更低 ,因为其他操作需要排序。
9.3.2.4 全外连接
完全外部联接是左外部联接和右外部联接的组合。
除了内部联接之外,两个表中未在内部联接结果中返回的行也将保留并扩展为空。换句话说,完全外部联接将表联接在一起,但在联接的表中显示没有相应行的行。
示例9-11 完全外部连接
以下查询检索每个部门中的所有部门和所有员工,但也包括:
? 任何没有部门的员工
? 任何没有员工的部门
SELECT d.department_id , e.employee_id
FROM employees e
FULL OUTER JOIN departments d
ON e.department_id = d.department_id
ORDER BY d.department_id ;
结果如下:
例9-12 完整外部连接的执行计划
从Oracle Database 11g 开始, Oracle Database 将自动使用基于散列连接的本机执行方法来执行完整的外部连接。当数据库使用新方法执行完整外部连接时,查询的执行计划包含散列连接完整外部。例 9-11 中的查询使用以下执行计划 :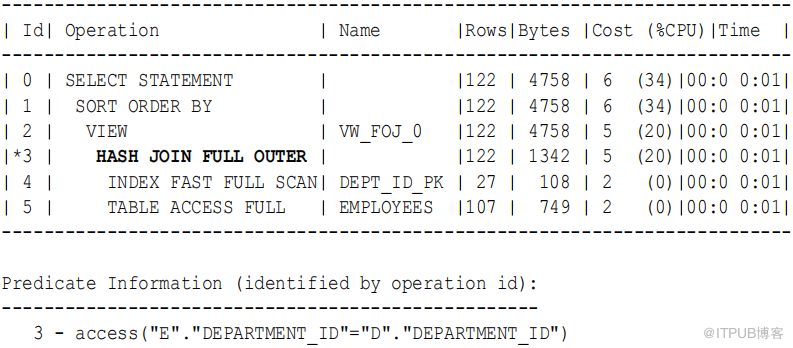
在前面的计划( 步骤 3) 中包含了散列连接完整外部,这表明查询使用散列完整外部连接执行方法。通常,当两个表之间的全外连接条件是等 值 连接时,可以使用散列全外连接执行方法,Oracle 数据库会自动使用它。
要指示优化器考虑使用散列全外连接执行方法,请应用NATIVE_FULL_OUTER_JOIN 提示。要指示优化器不要考虑使用散列完整外连接执行方法,请应用 NO_NATIVE_FULL_OUTER_JOIN 提示。 NO_NATIVE_FULL_OUTER_JOIN 提示指示优化器在连接每个指定表时排除本机执行方法。相反,完整的外部连接是作为左外部连接和反连接的联合执行的。
9.3.2.5 外部连接左侧有多个表
在Oracle 数据库 12c 中,一个外连接表的左侧可能存在多个表。
此增强功能使Oracle 数据库能够合并包含多个表的视图,并显示在外部连接的左侧。在 Oracle 数据库 12c 之前的版本中,像下面这样的查询是无效的,并且会触发 ORA-01417 错误消息 :
SELECT t1.d , t3.c
FROM t1 , t2 , t3
WHERE t1.z = t2.z
AND t1.x = t3.x (+)
AND t2.y = t3.y (+);
从Oracle 数据库 12c 开始,前面的查询是有效的。
9.3.3 半连接Semijoins
半联接是两个数据集之间的联接,当子查询数据集中存在匹配的行时,该联接返回第一个数据集中的行。
数据库在第一次匹配时停止处理第二个数据集。因此,当第二个数据集中的多行满足子查询条件时,优化不会复制第一个数据集中的行。
注:
半联接 Semijoins 和反联接antijoins 被视为联接类型,即使导致它们的 SQL 构造是子查询。它们是内部算法,优化器使用它们来展开子查询结构,以便它们可以以类联接的方式进行解析。
9.3.3.1 优化器 何时 考虑半联接
当查询只需要确定匹配是否存在时,半联接避免返回大量行。
对于大型数据集,这种优化可以大大节省嵌套循环联接的时间,嵌套循环联接必须遍历内部查询为外部查询中的每一行返回的每条记录。优化器可以将半联接优化应用于嵌套循环联接、哈希联接和排序合并联接。
优化器可以在以下情况下选择半联接:
? 语句使用 IN 或 EXISTS 子句。
? 语句在 in 或 EXISTS 子句中包含子查询。
?IN 或 EXISTS 子句不包含在 or 分支中。
9.3.3.2 半连接的工作原理
根据使用的连接类型,半连接优化的实现方式不同。
以下伪代码显示嵌套循环联接的半联接:
在前面的伪代码中,ds1 是第一个数据集, ds2_subquery 是子查询数据集。代码从第一个数据集获取第一行,然后循环子查询数据集以查找匹配项。代码一旦找到匹配项就退出内部循环,然后开始处理第一个数据集中的下一行。
示例9-13 使用 WHERE EXISTS 的半联接
以下查询使用WHERE EXISTS 子句仅列出包含员工的部门:
SELECT department_id , department_name
FROM departments
WHERE EXISTS
( SELECT 1
FROM employees
WHERE employees.department_id = departments.department_id )
执行计划在步骤1 中显示嵌套循环半 连接 :

对于构成外部循环的departments 中的每一行,数据库获取 department ID ,然后探测 employees.department_ID 索引以查找匹配条目。从概念上讲,索引如下:
10,rowid
10,rowid
10,rowid
10,rowid
30,rowid
30,rowid
30,rowid
...
如果departments 表中的第一个条目是 department 30 ,则数据库将对索引执行范围扫描,直到找到第一个 30 条目,然后停止读取索引并从 departments 返回匹配的行。如果外层循环中的下一行是 department 20 ,那么数据库将扫描索引以查找 20 条目,但找不到任何匹配项,然后执行外层循环的下一次迭代。数据库以这种方式进行,直到返回所有匹配的行。
示例9-14 在中使用的半联接
以下查询使用IN 子句仅列出包含员工的部门:
SELECT department_id , department_name
FROM departments
WHERE department_id IN ( SELECT department_id FROM employees );
执行计划在步骤1 中显示嵌套循环半 连接: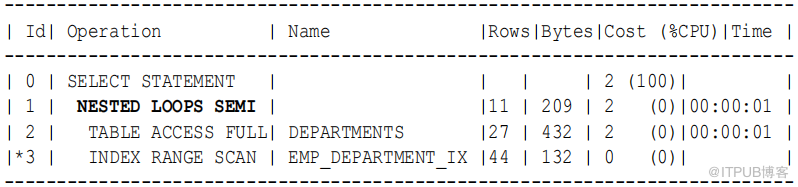
该计划与例9-13 中的计划相同。
9.3.4 反连接 Antijoins
反联接是两个数据集之间的联接,当子查询数据集中不存在匹配的行时,反联接返回第一个数据集中的行。
与半联接一样,反联接在找到第一个匹配项时停止处理子查询数据集。与半联接不同,反联接只在找不到匹配项时返回行。
9.3.4.1 优化器 何时 考虑反联接
当查询只需要在不存在匹配时返回行时,反联接避免了不必要的处理。
对于大型数据集,这种优化可以比 嵌套循环连接 节省大量时间。后者通过外部查询中每一行的内部查询返回的每条记录进行循环。优化器可以将反联接优化应用于 嵌套循环 联接、哈希联接和排序合并联接
优化器可以在以下情况下选择反联接:
? 语句使用 NOT IN 或 NOT EXISTS 子句。
? 语句在 NOT in 或 NOT EXISTS 子句中有一个子查询。
?NOT IN 或 NOT EXISTS 子句未包含在或分支中。
语句执行外 连接 并对联接列应用IS NULL 条件,如下例所示:
SET AUTOTRACE TRACEONLY EXPLAIN
SELECT emp. *
FROM emp , dept
WHERE emp.deptno = dept.deptno (+)
AND dept.deptno IS NULL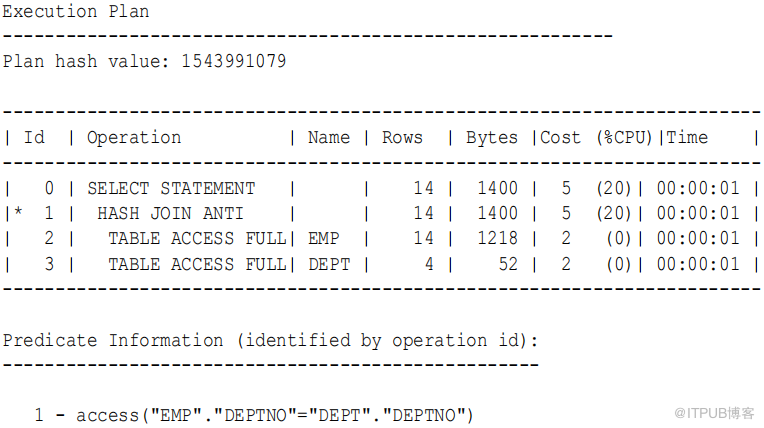
9.3.4.2 反连接的工作原理
根据使用的连接类型,反连接优化的实现方式不同。
以下伪代码显示嵌套循环联接的反联接:
在前面的伪码中,ds1 是第一个数据集, ds2 是第二个数据集。代码从第一个数据集获取第一行,然后循环通过第二个数据集寻找匹配项。代码一旦找到匹配项就退出内部循环,并开始处理第一个数据集中的下一行。
示例9-15 使用 WHERE EXISTS 的半联接
以下查询使用WHERE EXISTS 子句仅列出包含员工的部门:
SELECT department_id , department_name
FROM departments
WHERE EXISTS
( SELECT 1
FROM employees
WHERE employees.department_id = departments.department_id )
显示 了嵌套循环半操作在步骤1 的 执行计划: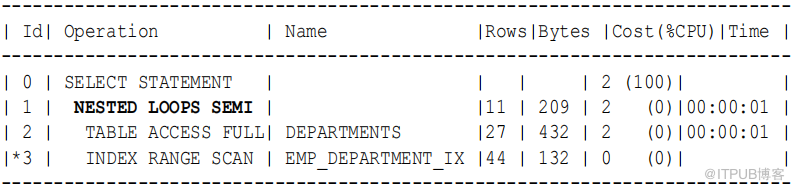
对于形成外部循环的部门中的每一行,数据库获取部门ID ,然后探测 employee .department_id 索引,以查找匹配的条目。从概念上看, 索引数据 如下:
10,rowid
10,rowid
10,rowid
10,rowid
30,rowid
30,rowid
30,rowid
...
如果departments 表中的第一个记录是 department 30 ,那么数据库将对索引执行一次范围扫描,直到找到第一个 30 项为止,这时它将停止读取索引并返回来自部门的匹配行。如果外层循环中的下一行是 department 20 ,那么数据库将扫描索引中的 20 项,并没有找到任何匹配项,从而执行外层循环的下一次迭代。数据库以这种方式处理,直到返回所有匹配的行。
9.3.4.3 反连接如何处理空值
对于半连接,IN 和 EXISTS 在功能上是等价的。但是,由于为空, NOT IN 和 NOT EXISTS 在功能上是不等价的。
如果将空值返回给NOT IN 操作符,则该语句将不返回任何记录。要查看原因,请考虑以下 WHERE 子句 :
WHERE department_id NOT IN ( null , 10 , 20 )
数据库对前面的表达式进行如下测试:
WHERE ( department_id != null )
AND ( department_id != 10 )
AND ( department_id != 20 )
为了使整个表达式为真,每个条件都必须为真。但是,一个空值不能与另一个值进行比较,所以department_id !=null 条件不能为真,因此整个表达式总是假的。即使在 NOT IN 操作符返回空值时,下列技术也可以使语句返回记录 :
? 对子查询返回的列应用 NVL 函数。
? 在子查询中添加一个非空谓词。
实现NOT NULL 约束。
与NOT In 不同, NOT EXISTS 子句只考虑返回匹配项存在的谓词,而忽略任何不匹配或由于 null 而无法确定的行。如果子查询中至少有一行与来自外部查询的行匹配,则 NOT EXISTS 返回 false 。如果没有元组匹配,则 NOT EXISTS 返回 true 。子查询中是否存在空值并不影响对匹配记录的搜索。
在Oracle Database 11g 之前的版本中,当可以通过子查询返回空值时,优化器不能使用反连接优化。然而,从 Oracle 数据库 11g 开始,下面几节中描述的 ANTI NA ( 和 ANTI SNA) 优化使优化器能够在可能为空的情况下使用反连接。
例9-16 反连接使用 NOT IN
假设用户使用NOT IN 子句发出以下查询,以列出不包含雇员的部门 :
SELECT department_id , department_name
FROM departments
WHERE department_id NOT IN ( SELECT department_id FROM employees );
前面的查询不返回行,即使几个部门不包含雇员。由于employees.department_id 列可为空,因此发生了用户不希望出现的此结果。
执行计划在步骤2 中显示嵌套循环反 SNA 操作: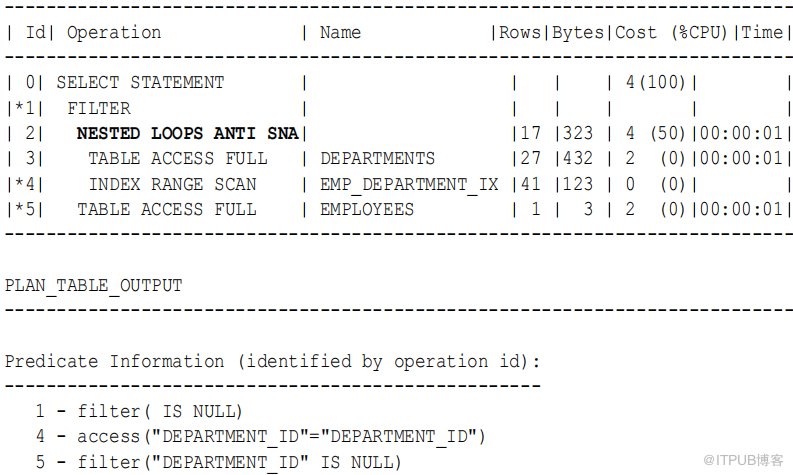
ANTI-SNA 代表 “ 单个支持空值的 antijoin” , ANTI-NA 代表 “ 支持空值的 antijoin” ,支持空值的操作使优化器可以在可空列上使用 antijoin 优化。在 Oracle Database 11g 之前的版本中,当可能为空时,数据库无法对不在查询执行反联接。
假设用户通过对子查询应用IS NOT NULL 条件重写查询:
SELECT department_id , department_name
FROM departments
WHERE department_id NOT IN
( SELECT department_id FROM employees WHERE department_id IS NOT NULL );
前面的查询返回16 行,这是预期的结果。计划中的步骤 1 显示标准嵌套循环反联接,而不是反 NA 或反 SNA 联接,因为子查询不能返回空: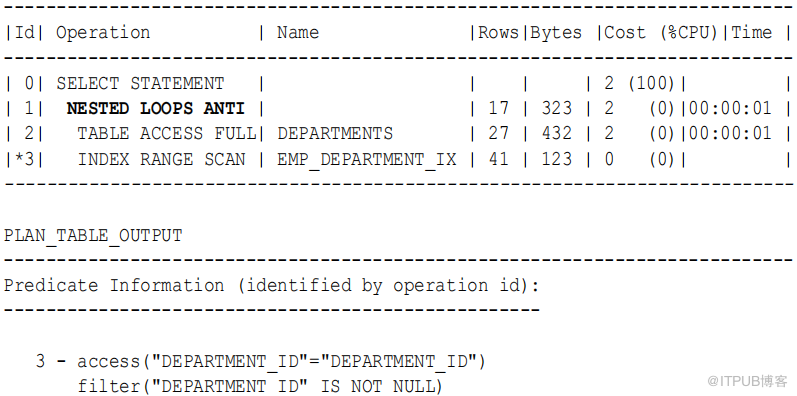
例9-17 反连接使用 NOT EXISTS
假设用户使用一个NOT EXISTS 子句发出以下查询,以列出不包含雇员的部门 :
SELECT department_id , department_name
FROM departments d
WHERE NOT EXISTS
( SELECT null FROM employees e WHERE e.department_id = d.department_id )
前面的查询避免了NOT IN 子句的 null 问题。因此 , 尽管 department_id 列可为空,该语句返回所需的结果。
执行计划的第1 步揭示了一个嵌套的循环反操作,而不是反 NA ,这是在可能为空时不进入所必需的: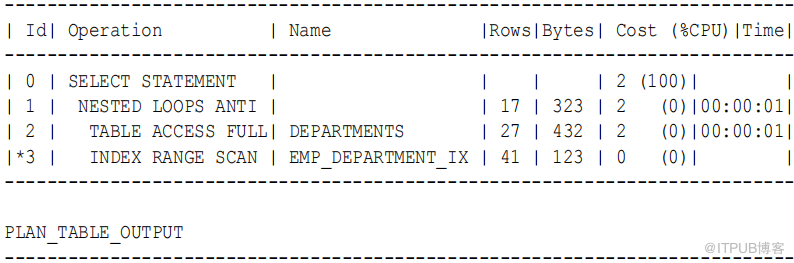

9.3.5 笛卡尔连接 Cartesian Joins
当一个或多个表对语句中的任何其他表没有任何联接条件时,数据库使用笛卡尔联接。
优化器将来自一个数据源的每一行与来自另一个数据源的每一行连接起来,创建这两个集合的笛卡尔积。因此,使用以下公式计算联接产生的行总数,其中rs1 是第一行集中的行数, rs2 是第二行集中的行数:
rs1 X rs2 = total rows in result set
9.3.5.1 优化器 何时 考虑笛卡尔连接时
优化器仅在特定情况下对两行源使用笛卡尔连接。通常,情况如下:
? 不存在连接条件。
在某些情况下,优化器可以在两个表之间选取一个公共筛选条件作为可能的联接条件。
注:
如果笛卡尔连接出现在查询计划中,则可能是由于不小心忽略了连接条件。一般来说,如果查询连接n 个表,则需要 n-1 连接条件来避免笛卡尔连接 。
? 笛卡尔连接是一种有效的方法。
例如,优化器可能决定生成两个非常小的表的笛卡尔积,这两个表都连接到同一个大表。
?ORDERED 提示在指定联接表之前指定表。
9.3.5.2 笛卡尔连接的工作原理
笛卡尔连接使用嵌套循环。
在较高级别上,笛卡尔连接的算法如下所示,其中ds1 通常是较小的数据集, ds2 是较大的数据集:
示例9-18 笛卡尔连接
在本例中,用户打算执行employees 和 departments 表的内部联接,但意外地忽略了联接条件:
SELECT e.last_name , d.department_name FROM employees e , departments d
执行计划如下: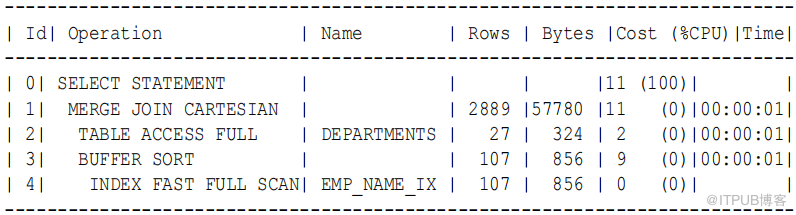
在前面计划的步骤1 中,笛卡尔关键字指示笛卡尔连接的存在。行数( 2889 )是 27 和 107 的乘积。
在步骤3 中,缓冲区排序操作指示数据库正在将通过扫描 emp_name_ix 获得的数据块从 SGA 复制到 PGA 。此策略避免了对数据库缓冲区缓存中相同块的多次扫描,这将生成许多逻辑读取并允许资源争用。
9.3.5.3 笛卡尔 连接 的 控制
ORDERED 提示指示优化器按照表在 FROM 子句中出现的顺序连接表。通过在两个没有直接连接的行源之间强制连接,优化器必须执行笛卡尔连接。
示例9-19 ORDERED Hint
在以下示例中,ORDERED 提示指示优化器联接 employees 和 locations ,但没有联接条件连接这两个行源:
SELECT /+ORDERED/
e.last_name , d.department_name , l.country_id , l.state_province
FROM employees e , locations l , departments d
WHERE e.department_id = d.department_id
AND d.location_id = l.location_id
下面的执行计划显示了位置(步骤6 )和员工(步骤 4 )之间的笛卡尔产品(步骤 3 ),然后将其连接到部门表(步骤 2 ):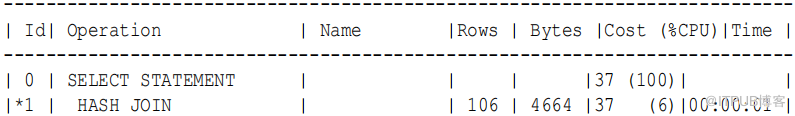

9.4 连接 优化
连接优化使连接更加有效。
9.4.1 Bloom 过滤器
Bloom filter 以其创建者 Burton Bloom 的名字命名,是一种用于测试集合成员资格的低内存数据结构。
一个Bloom filter 可以正确地指示一个元素何时不在集合中,但也可以不正确地指示一个元素何时在集合中。因此,不可能出现 漏报 ,但可能出现 误报 。
9.4.1.1 Bloom 过滤器的用途
Bloom 过滤器测试一组值,以确定它们是否是另一组值的成员。
例如,一个集合是(10,20,30,40) ,另一个集合是 (10,30,60,70) 。一个 Bloom filter 可以确定 60 和 70 被排除在第一个集合之外, 10 和 30 可能是成员。当存储筛选器所需的内存相对于数据集中的数据量比较小,并且大多数数据预期无法通过成员资格测试时, Bloom 筛选器特别有用。
Oracle 数据库使用 Bloom filter 来实现各种特定的目标,包括 :
? 减少在并行查询中传输到从属进程的数据量,特别是当数据库因为没有满足联接条件而丢弃大多数行时
? 在连接中构建分区访问列表时,删除不需要的分区,这称为分区修剪
? 测试数据是否存在于服务器结果缓存中,从而避免磁盘读取
?Exadata 单元中的筛选器成员,特别是在将一个大的事实表和一个星型模式中的小维度表连接起来时,可以同时进行并行处理和串行处理。
9.4.1.2 Bloom 过滤器的工作原理
Bloom 过滤器使用一个比特数组来表示集合中的包含。
例如,数组中的8 个元素 ( 本例中使用的任意数字 ) 最初设置为 0:
e1 e2 e3 e4 e5 e6 e7 e8 - 0 0 0 0 0 0 0
这个数组表示一个集合。为了表示这个数组中的输入值i ,对 i 应用了三个独立的哈希函数 ( 三个是任意的 ) ,每个函数生成 1 到 8 之间的哈希值 :
f1(i) = h1
f2(i) = h2
f3(i) = h3
例如,为了在这个数组中存储值17 ,哈希函数将 i 设置为 17 ,然后返回以下哈希值 :
f1(17) = 5
f2(17) = 3
f3(17) = 5
在前面的示例中,两个哈希函数碰巧返回了相同的值5 ,这称为哈希冲突。因为不同的哈希值是 5 和 3 ,所以数组中的第 5 和第 3 个元素被设置为 1:
e1 e2 e3 e4 e5 e6 e7 e8 - 0 1 0 1 0 0 0
测试集合中17 个成员的成员资格将逆转该过程。要测试集合是否排除值 17 ,元素 3 或元素 5 必须包含 0 。如果任何一个元素中都有 0 ,那么集合就不能包含 17 。不可能有假阴性。
为了测试集合是否包含17 ,元素 3 和元素 5 都必须包含 1 个值。但是,如果测试表明两个元素都是 1 ,那么集合仍然可能不包含 17 。误报是可能的。例如,下面的数组可能表示值 22 ,其中元素 3 和元素 5 都有一个 1:
e1 e2 e3 e4 e5 e6 e7 e8 - 0 1 0 1 0 0 0
9.4.1.3 Bloom 过滤器控制
优化器会自动决定是否使用Bloom 过滤器。要覆盖优化器决策,请使用提示 PX_JOIN_FILTER 和 NO_PX_JOIN_FILTER 。
9.4.1.4Bloom 滤元数据
V$ views 包含关于 Bloom 过滤器的元数据。您可以查询以下视图 :
?V$SQL_JOIN_FILTER
这个视图显示了由活动的Bloom 过滤器过滤出 ( 过滤列 ) 和测试 ( 探测列 ) 的行数。
?V$PQ_TQSTAT
此视图显示在执行树的每个阶段,通过每个并行执行服务器处理的行数。您可以使用它来监视Bloom 过滤器减少了多少并行进程之间的数据传输。
在执行计划中,Bloom 过滤器由 Operation 列中的关键字 JOIN filter 和 Name 列中的前缀 :BF 表示,如下面的计划片段的第 9 步所示 :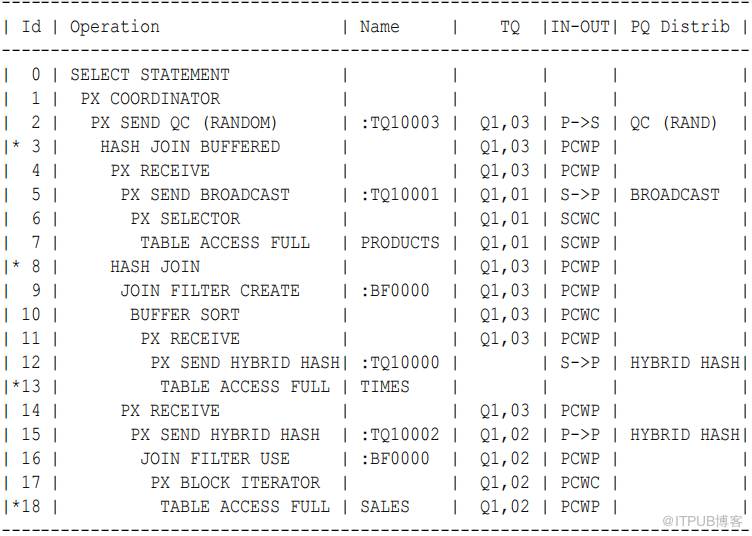
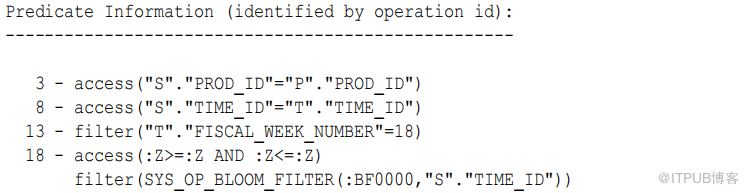
单个服务器进程扫描时间表(步骤13 ),然后使用混合哈希分布方法将行发送到并行执行服务器(步骤 12 )。集合 Q1,03 中的过程创建一个 bloom 过滤器(步骤 9 )。 集合 Q1,02 中的进程并行扫描 sales (步骤 18 ),然后使用 Bloom 过滤器丢弃 sales 中的行(步骤 16 ),然后使用混合散列分布将它们发送到 集合 Q1,03 (步骤 15 )。集合 Q1,03 散列中的进程将时间行连接到筛选的销售行(步骤 8 )。集合 Q1,01 中的进程扫描产品(步骤 7 ),然后将行发送到 Q1,03 (步骤 5 )。最后, Q1,03 中的进程将产品行与前一个散列联接生成的行联接(步骤 3 )。
下图说明了基本过程。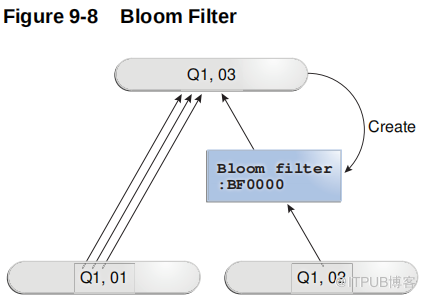
9.4.2Partition-Wise 分区 连接
分区连接是将两个表的大连接( 其中一个表必须在连接键上分区 ) 划分为几个较小的连接的优化。
分区连接是以下任何一种:
?完整 partition-wise 加入
这两个表必须在它们的连接键上均分,或者使用引用分区( 即通过引用约束关联 ) 。数据库将大的连接分成两个分区之间的小的连接,这两个分区分别来自两个连接的表。
?部分 partition-wise 连接
在联接键上只对一个表进行分区。另一个表可以分区,也可以不分区。
9.4.2.1 分区连接的目的
分区连接通过减少并行执行连接时在并行执行服务器之间交换的数据量来减少查询响应时间。
这种技术显著减少了响应时间,提高了CPU 和内存的使用。在 Oracle Real Application Clusters (Oracle RAC) 环境中,分区连接还可以避免或至少限制互连上的数据流量,这是实现大规模连接操作的良好可伸缩性的关键。
9.4.2.2 分区连接 工作原理
当数据库连续连接两个分区表而不使用分区连接时,单个服务器进程执行该连接。
在下面的示例中,连接不是分区方式的,因为服务器进程将表t1 的每个分区连接到表 t2 的每个分区。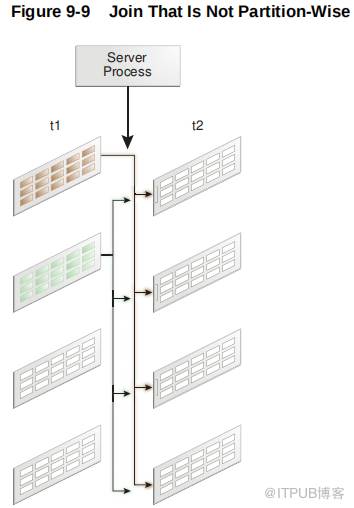
9.4.2.2.1 完全分区连接的工作方式
数据库以串行或并行方式执行完全分区连接。
下图显示了并行执行的完全分区连接。在这种情况下,并行度的粒度就是一个分区。每个并行执行服务器成对地连接分区。例如,第一个并行执行服务器将t1 的第一个分区连接到 t2 的第一个分区。然后并行执行协调器组装结果。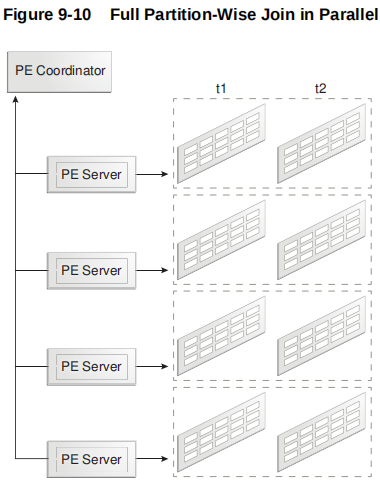
完全分区连接也可以将分区连接到子分区,这在表使用不同的分区方法时非常有用。例如,客户按散列划分,而销售按范围划分。如果您通过散列对sales 进行分区,那么数据库可以在客户的散列分区和 sales 的散列分区之间执行完全分区连接。
在执行计划中,在连接之前出现分区操作表示存在完全分区连接,如下面的代码段所示: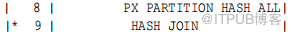
9.4.2.2.2 部分分区连接的 工作原理
与完全分区连接不同,部分分区连接必须并行执行。
下图显示了t1( 已分区 ) 和 t2( 未分区 ) 之间的部分分区连接。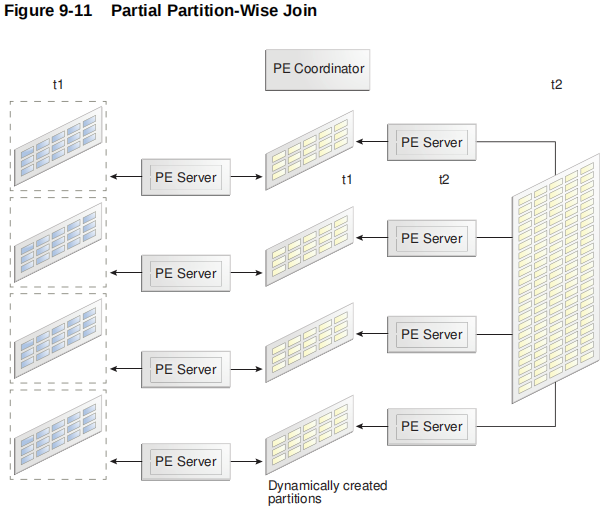
因为t2 没有分区,所以一组并行执行服务器必须根据需要从 t2 生成分区。然后,一组不同的并行执行服务器将 t1 分区连接到动态生成的分区。并行执行协调器组装结果。
在执行计划中,PX 操作发送分区 (KEY) 信号一个局部分区连接,如下面的代码段所示 :
| 11 | PX SEND PARTITION (KEY) |
9.4.3 内存连接组
联接组是用户创建的对象,它列出两个或多个可以有意义地联接的列。
在某些查询中,联接组消除了对列值进行解压缩和散列的性能开销。联接组需要内存中的列存储(IM 列存储)。
