通常情况下,做网站的都会给自己的网站添加一个Icon,浏览器上一长排的标签页,用Icon来区分就显得更加醒目。现在想找一个没有Icon的网站并不好找,可见没有Icon的网站是多么的业余啊。"什么?你问Icon是什么?你走吧,这是讨论技术的地方!"

想知道如何获取Icon,就要弄明白怎样设置Icon。先讨论一下设置Icon,再介绍获取Icon,并提供相应Java代码以供参考。
一. 设置网站Icon
设置Icon有两种方式:
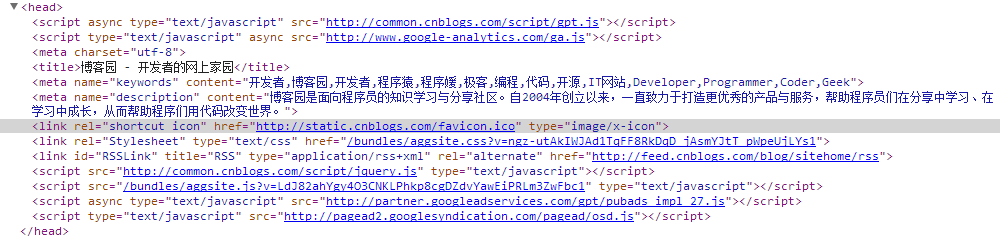
1. 看一下我们专业的博客园,看到灰色部分了吗,在head标签中有个link标签,将rel设置为"shortcut icon",href 设置为Icon的位置,type设置成实际图标类型就OK了。这个Icon文件不是必须以favicon.ico命名,也可以选择png等其他格式的图片。
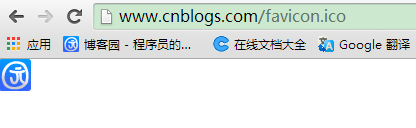
2. 如果用第一种方式,每个页面都要写link,是不是挺麻烦的,可能会用模板之类的东西自动生成,这个我不懂啦。如果浏览器发现html中没有写明Icon位置,就自动到网站根目录下尝试读取favicon.ico文件。再看一下我们专业的博客园,看到了吗,Icon显示出来了。注意:根目录下的文件就必须以favicon.ico命名了。考虑到浏览器兼容性,大部分的网站除了在html中指定Icon的位置,同时也会在网站根目录下存放Icon文件。
二. 获取网站Icon
知道怎么设置Icon,获取Icon就很简单了。解析html相对来说比较麻烦,可以直接到网站根目录下尝试读取favicon.ico。如果没有,再解析html(话说我试了很多常用网站,都可以从根目录下读取,想找个根目录下不存放Icon的网站还真不容易,这时我想到了12306,试了一下果然没有啊,事情并没有想象的那么简单,12306会奇葩到你想不到,后边再说)。思路就是这样,很简单,但是在实现的过程中会有很多细节问题。用java代码实现一下吧,并详细说明可能遇到的细节问题。
下边是获取Icon地址的入口函数,传入网络地址即可。
// 获取Icon地址
public static String getIconUrlString( String urlString ) throws MalformedURLException {
urlString = getFinalUrl( urlString );
URL url = new URL( urlString );
String iconUrl = url.getProtocol() + "://" + url.getHost() + "/favicon.ico";// 保证从域名根路径搜索
if ( hasRootIcon( iconUrl ) )
return iconUrl;
return getIconUrlByRegex( urlString );
}getFinalUrl是获取网址经过3XX跳转之后的url地址,如果没有跳转就返回原来的url。防止有些网址会出现跳转的情况,所以先搞到跳转之后的网址在进行获取。java的HttpUrlConnection默认情况下会自动跳转,为什么还要手动获取呢?比如www.rayli.com会跳转到www.rayli.com.cn,我要访问 www.rayli.com/favicon.ico,我希望跳转到www.rayli.com.cn/favicon.ico。但实际情况却跳转到了www.rayli.com.cn,这样就造成我判断错误,所以需要手动解析跳转后的地址。
hasRootIcon函数判断网站根目录下是否存在favicon.ico文件,注意在传入url之前要保证传入的是根路径地址,因为有些网站跳转过后并不是跳转到根目录,当正常响应并且存在返回内容时就认为有指定文件。getConnection函数是根据url获取一个HttpUrlConnection。
// 判断在根目录下是否有Icon
private static boolean hasRootIcon( String urlString ) {
HttpURLConnection connection = null;
try {
connection = getConnection( urlString );
connection.connect();
return HttpURLConnection.HTTP_OK == connection.getResponseCode() && connection.getContentLength() > 0;
}
catch ( Exception e ) {
e.printStackTrace();
return false;
}
finally {
if ( connection != null )
connection.disconnect();
}
}getIconUrlByRegex是根据正则表达式从html中获取Icon地址,getHead方法是获取网页的head结束标签之前的文本,然后用正则表达式匹配内容,这里的正则表达式有两个,这是因为rel和href的顺序是不固定的。匹配到以后判断一下是否为相对路径,如果是的话做进一步处理。
private static final Pattern[] ICON_PATTERNS = new Pattern[] {
Pattern.compile( "rel=[\"']shortcut icon[\"'][^\r\n>]+?((?<=href=[\"']).+?(?=[\"']))" ),
Pattern.compile( "((?<=href=[\"']).+?(?=[\"']))[^\r\n<]+?rel=[\"']shortcut icon[\"']" ) };// 从html中获取Icon地址
private static String getIconUrlByRegex( String urlString ) {
try {
String headString = getHead( urlString );
for ( Pattern iconPattern : ICON_PATTERNS ) {
Matcher matcher = iconPattern.matcher( headString );
if ( matcher.find() ) {
String iconUrl = matcher.group( 1 );
if ( iconUrl.contains( "http" ) )
return iconUrl;
if ( iconUrl.charAt( 0 ) == '/' ) {//判断是否为相对路径或根路径
URL url = new URL( urlString );
iconUrl = url.getProtocol() + "://" + url.getHost() + iconUrl;
}
else {
iconUrl = urlString + "/" + iconUrl;
}
return iconUrl;
}
}
}
catch ( Exception e ) {
e.printStackTrace();
}
return null;
}三. 测试一下
整个流程就是这样的,测试一下吧,爬取hao123的一级域名,一共一百多个。代码如下,没啥好说的,结果显示除了没有Icon的网站和不能正常响应的网站,都可以得到Icon地址。但是,有一个网站除外,那就是我们伟大的12306。访问www.12306.cn时,其中有一段js,判断如果网址是www.12306.cn则locayion到http://www.12306.cn/mormhweb/。我靠,你用js跳转我就直接没辙了。哎,随它去吧,各位可知道用js跳转的坏处呀,如果禁用了js你看到的就是白花花的一片,像棉花、像银子、像白云、像一张白纸啊,亲,我的想象力又被你激发了!
// 爬取一级域名
private static Set<String> getUrls( String urlString ) {
Set<String> urlSet = new HashSet<String>();
Pattern pattern = Pattern
.compile( "(http|https)://www\\..+?\\.(aero|arpa|biz|com|coop|edu|gov|info|int|jobs|mil|museum|name|nato|net|org|pro|travel|[a-z]{2})" );
Matcher matcher = pattern.matcher( getHtml( urlString ) );
while ( matcher.find() ) {
urlSet.add( matcher.group() );
}
return urlSet;
}public static void main( String[] args ) throws IOException {
long startTime = System.currentTimeMillis();
Set<String> urlSet = getUrls( "http://www.hao123.com/" );
for ( String urlString : urlSet ) {
System.out.println( urlString );
System.out.println( getIconUrlString( urlString ) );
}
System.out.println( urlSet.size() );
System.out.println("耗时:"+(System.currentTimeMillis() - startTime)+" ms" );
}特殊情况比较多,代码肯定有不完善的地方,欢迎交流指正,完整代码供下载: IconFinder.java
