本文只介绍Kettle最基础的操作,适用于初次学习使用Kettle,关于更加详细的操作指南,后续将会陆续推出。
官网: https://community.hitachivantara.com/s/article/data-integration-kettle
安装
下载、解压缩、安装JDK
下载Kettle,目录结果如下:
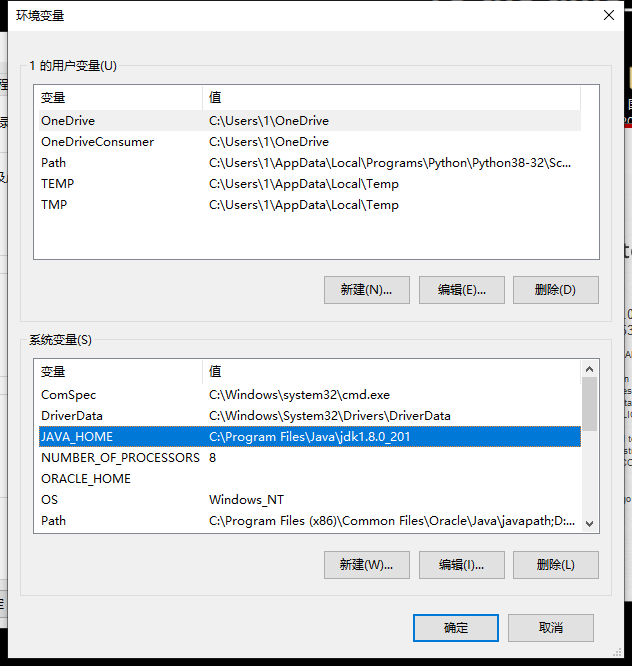
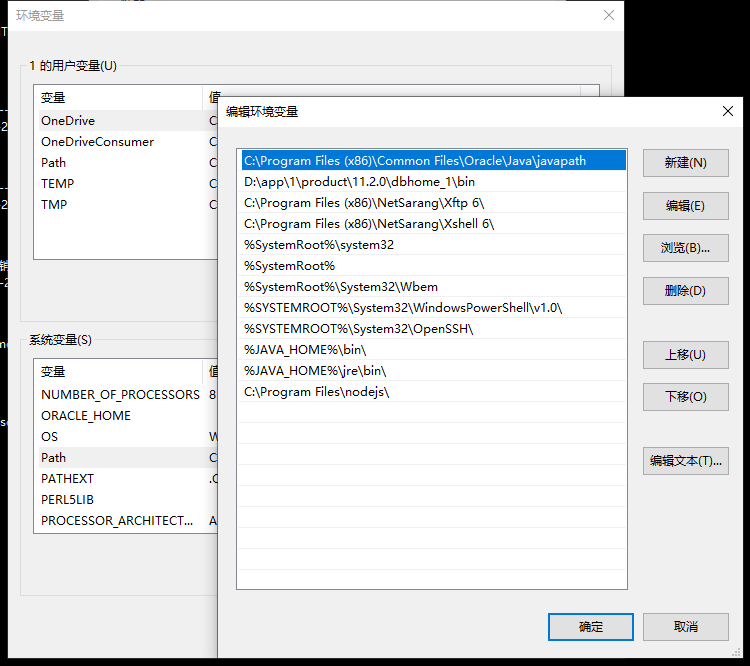
安装JDK,配置JAVA_HOME环境变量:
启动测试,运行kettle文件夹下的Spoon.bat(linux环境下为Spoon.sh)
核心概念
转换Transform,ETL基本组件,处理数据,包括一个或者多个步骤Step,Step可以是读取数据、处理数据、保存数据等。Transform专注于数据处理。
作业Job,一个完整的工作流程,其内部组件可以是Transform,也可以是其他的Job。Job还可以是邮件处理、FTP、脚本、文件资源管理、等。
从Spoon开始 认识Transform
Spoon,转换Transform设计工具(GUI),运行kettle文件夹下的Spoon.bat(linux环境下为Spoon.sh)启动;
本节只做为基础演示,不会完全遵从实际项目使用规范,例如统一的数据源配置、第一步先配置i资源库等,我们从最感兴趣的地方开始;
新建转换
左侧为控件树,包含丰富的数据处理步骤Step方法。
这里我们以一个传统的数据库对数据库做一个简单的Transform。
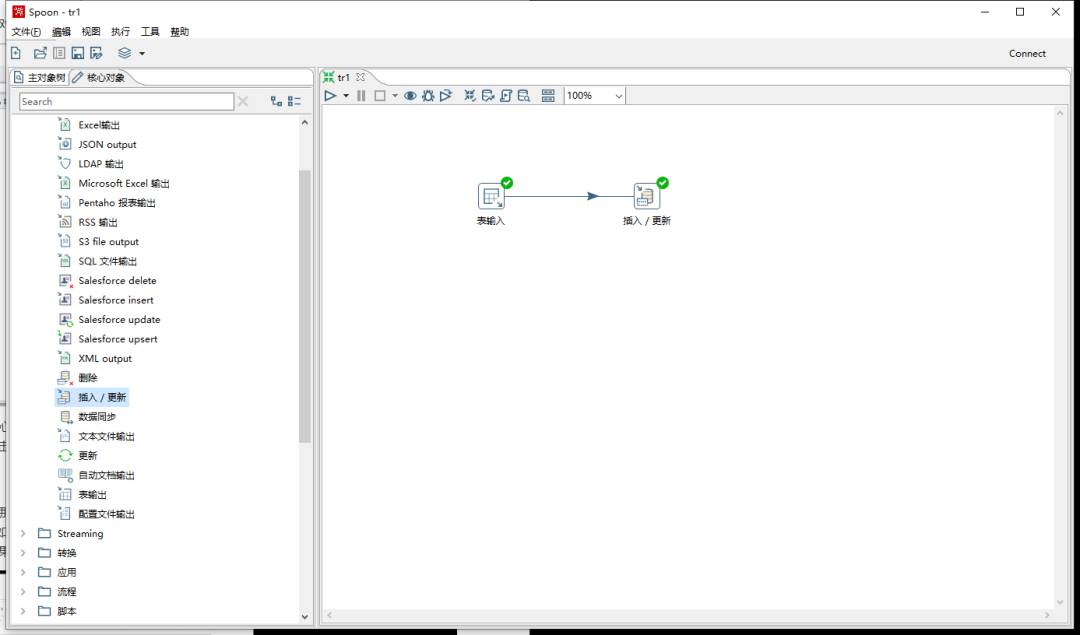
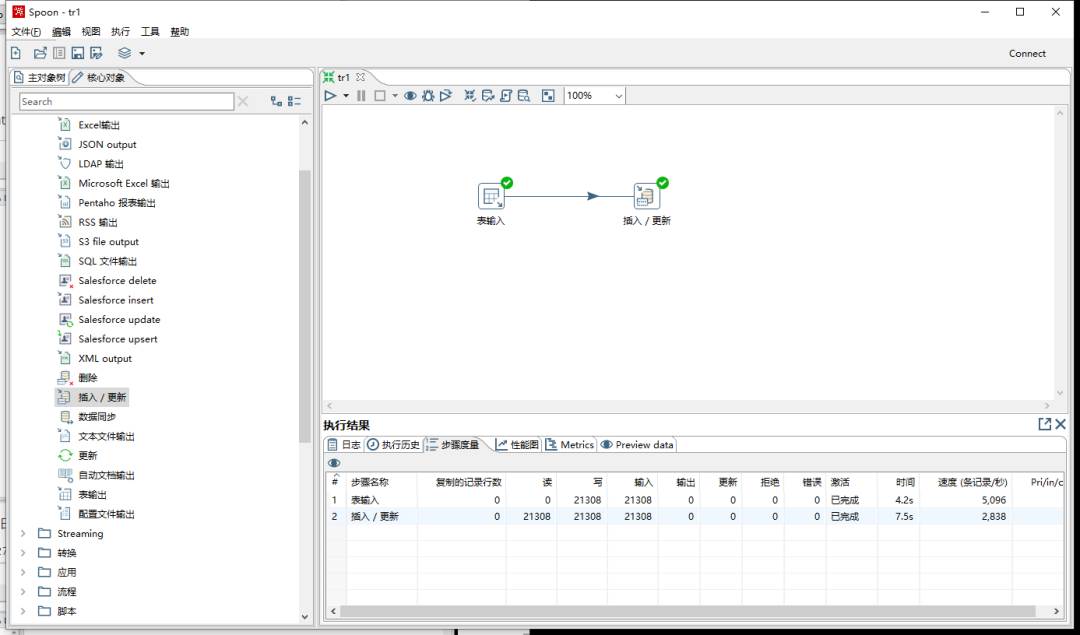
在左侧对象列表依次选择:核心对象>输入>表输入、核心对象>输出>插入/更新,便可以得到上图的结果,他们都是Transform的步骤Step;
操作提示:双击对象直接添加,按住Shift可以创建连线,点击连线置灰使连线失效,双击Step打开编辑,双击空白处可以编辑整个Transform,工具栏可以打开很多有用的工具包括最有用的校验工具。
表输入
这里选择的是Oracle数据库,那么这里需要准备好jdbc的jar包;复制Oracle客户端中的jdbc/lib下的所有jar包至kettle的lib目录下;(Oracle如果安装在本地,jdbc路径如下,如果只安装了客户端Client,在类似Client_1的目录下也能找到jdbc文件夹,如果都没有安装,没有关系,从其他地方拷贝过来一样可以用。)
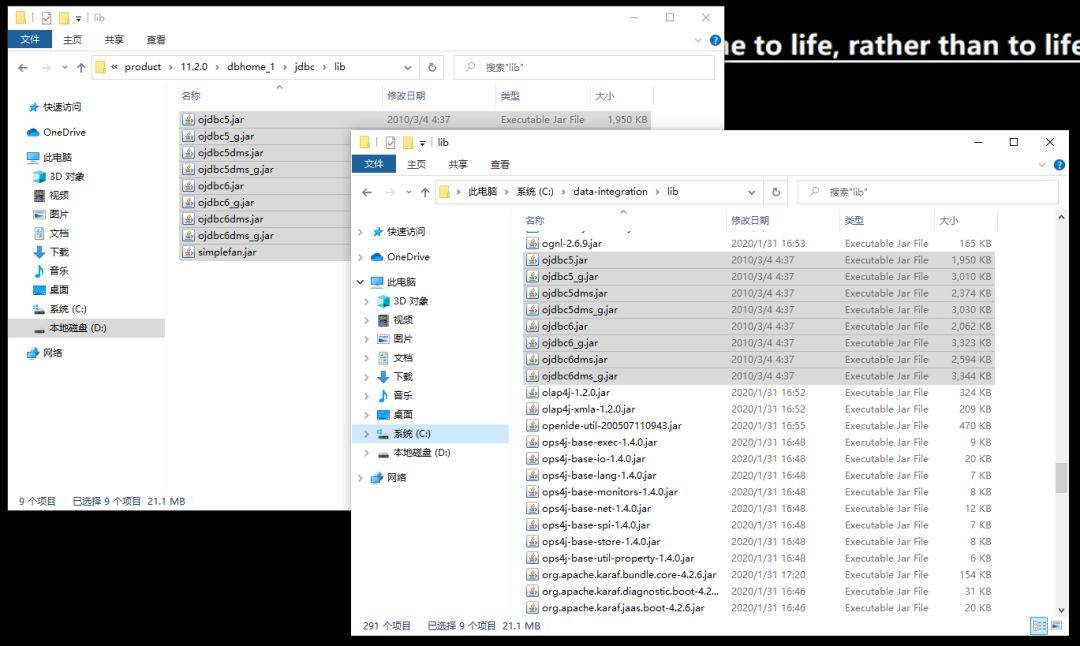
拷贝完成之后需要重启kettle方能生效;
新建数据库连接;
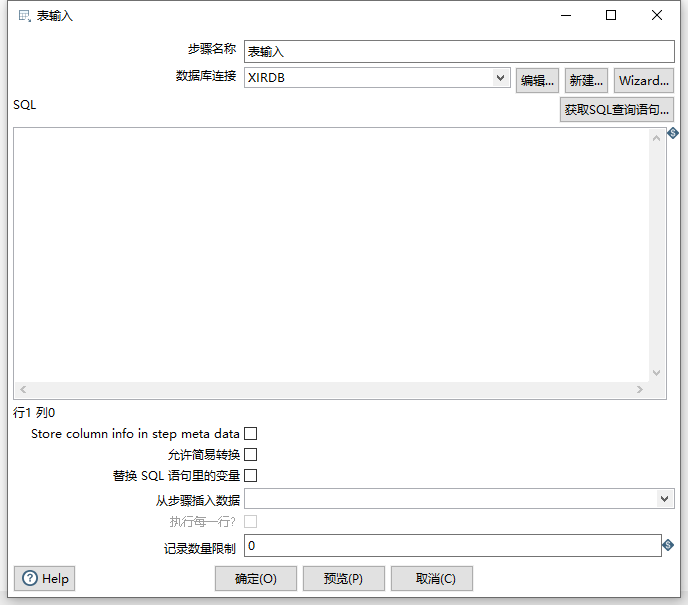
这里选择的是Oracle的源;
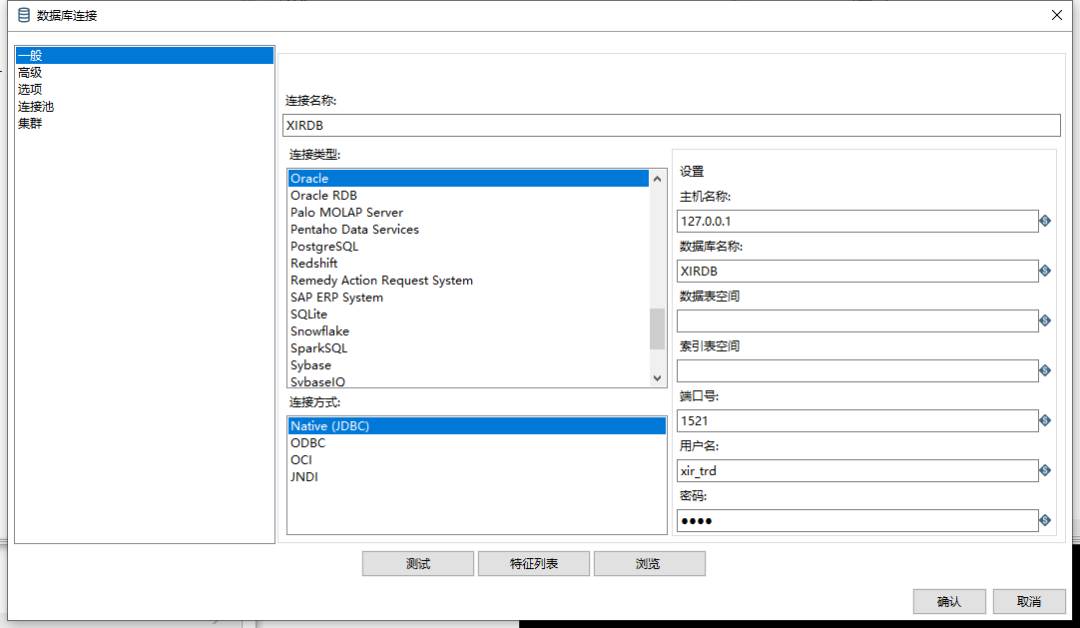
编辑完成测试连接是否通过;
返回表输入,填写SQL;
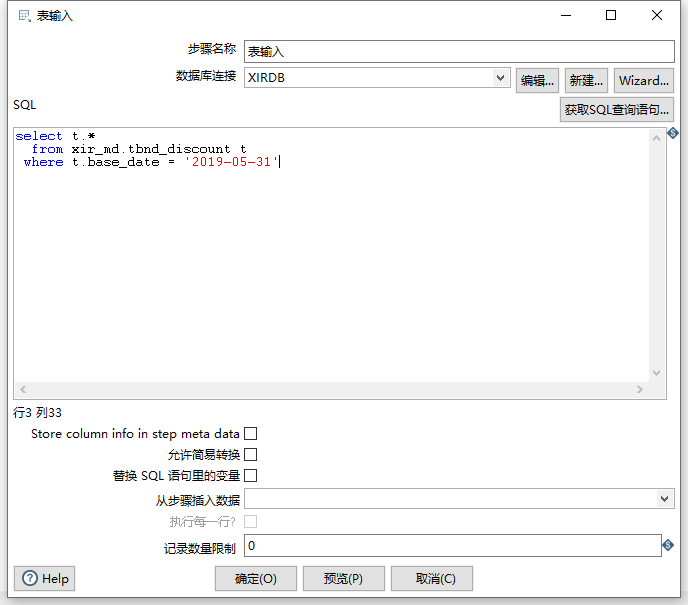
预览检验脚本查询结果;
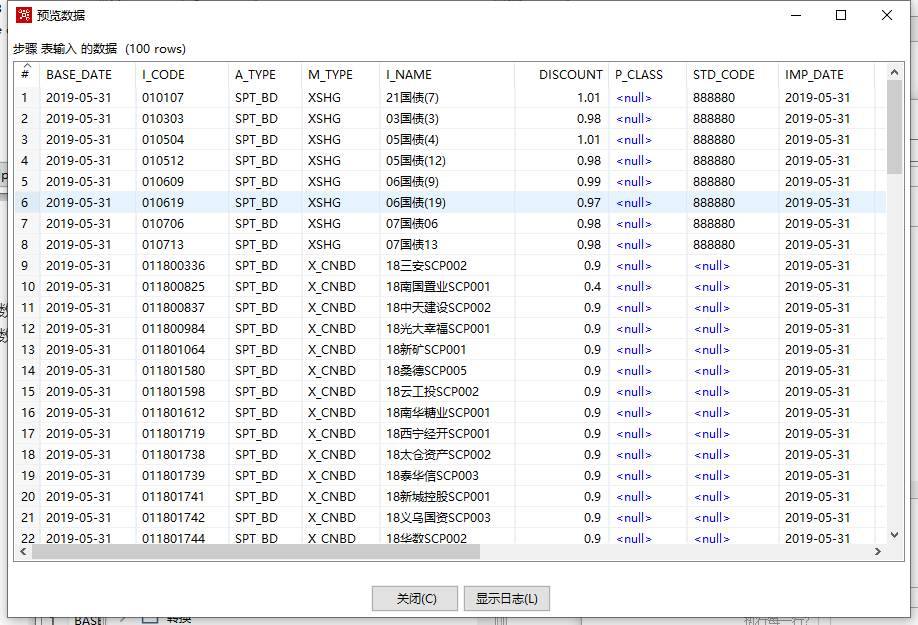
确定保存。
插入/更新
同样的方法新增数据库连接,目标模式为数据库用户,之后获取字段,如下:(注意,”用来查询的关键字“和更新有关,需配置为数据表的唯一索引。)
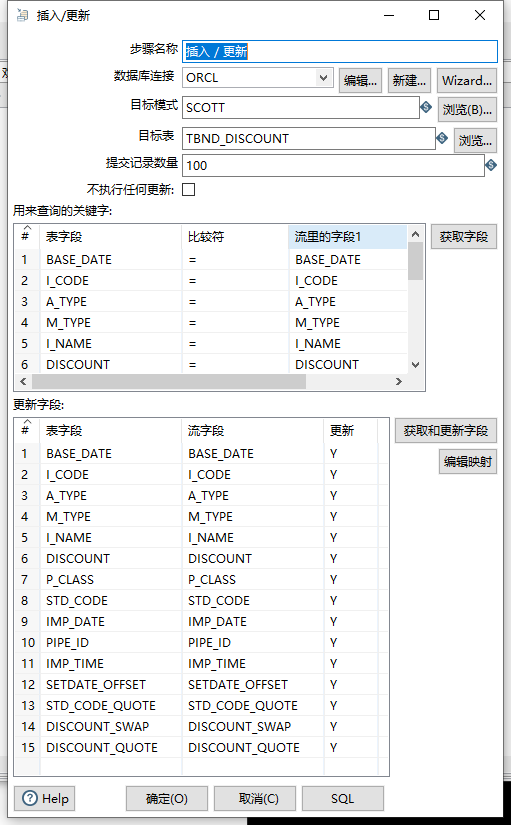
确定保存。
测试
启动测试,默认配置选择”Pentaho local“,即本地测试;
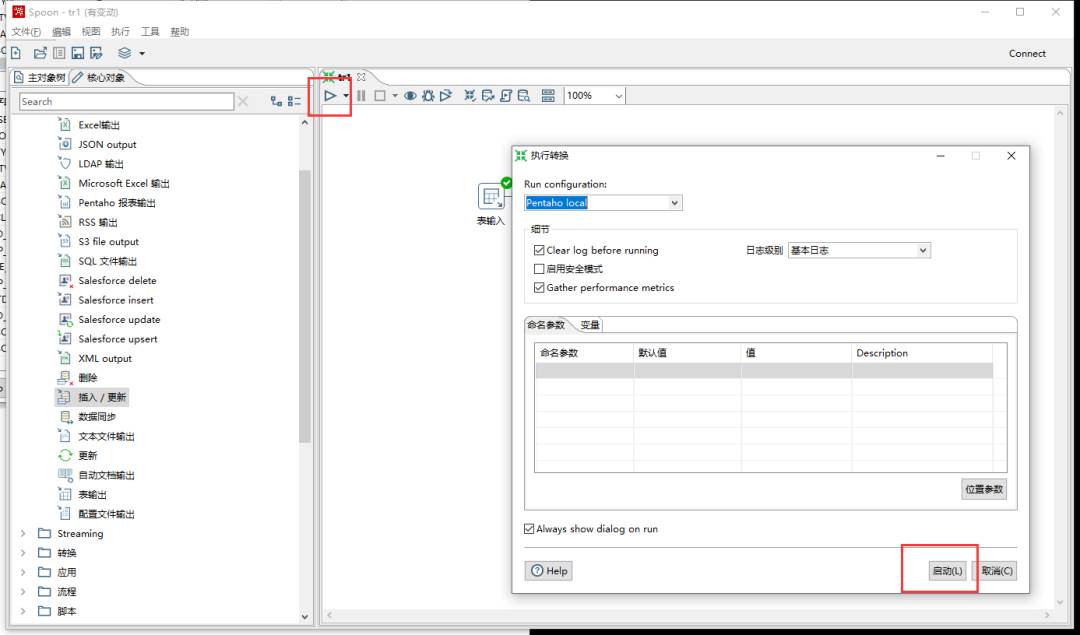
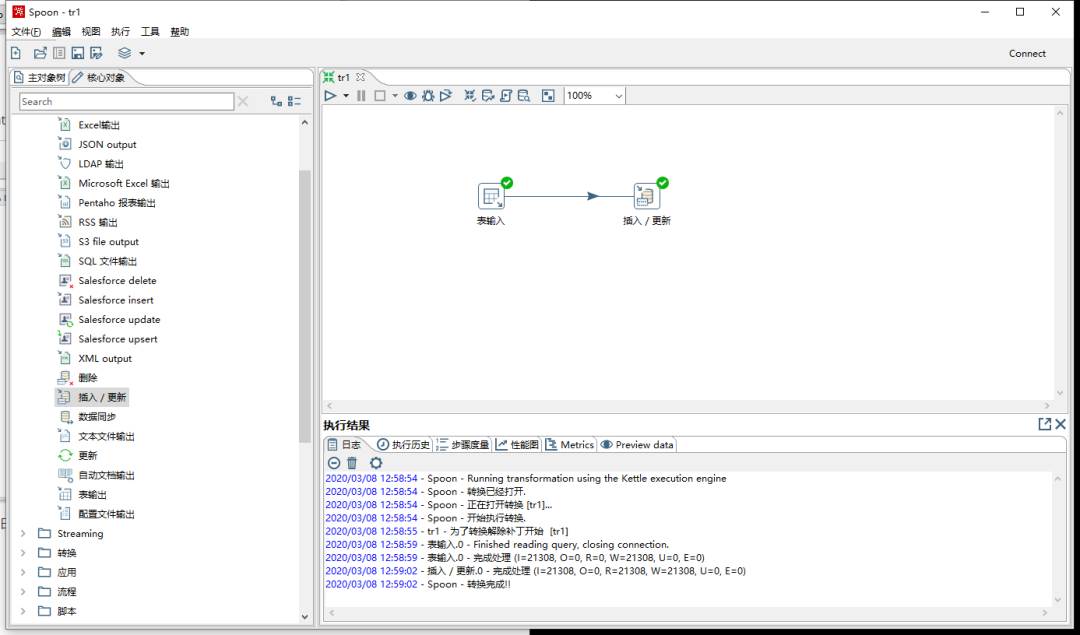
在下方执行结果可以看到相关日志;
从Spoon开始 认识Job
新建任务
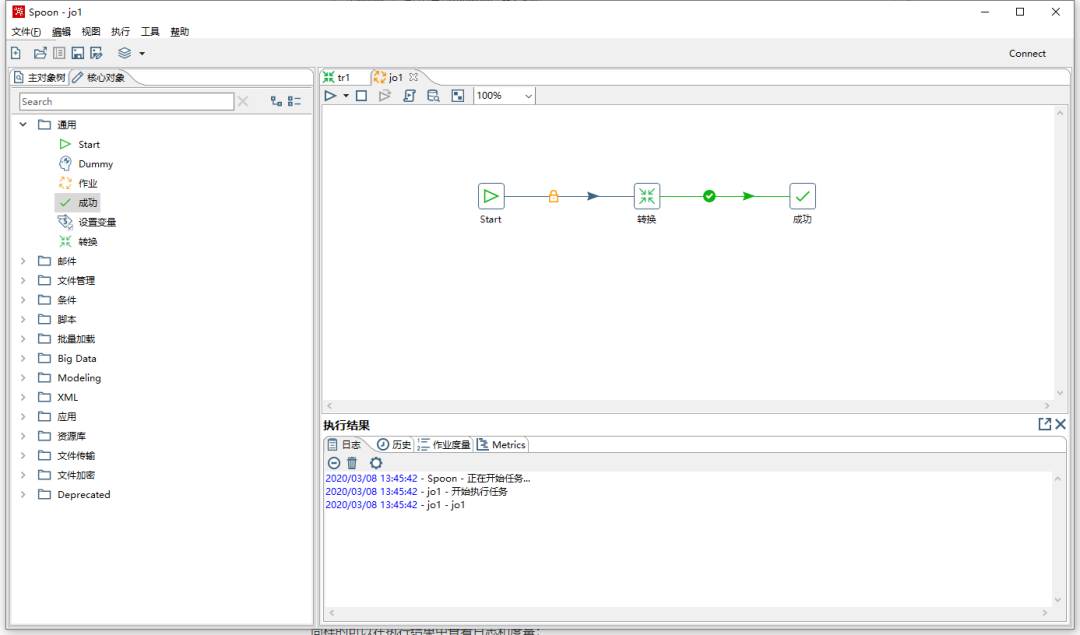
与新建Transform类似,依次添加开始,转换,成功,那么这个Job的功能就是运行一个Transform;
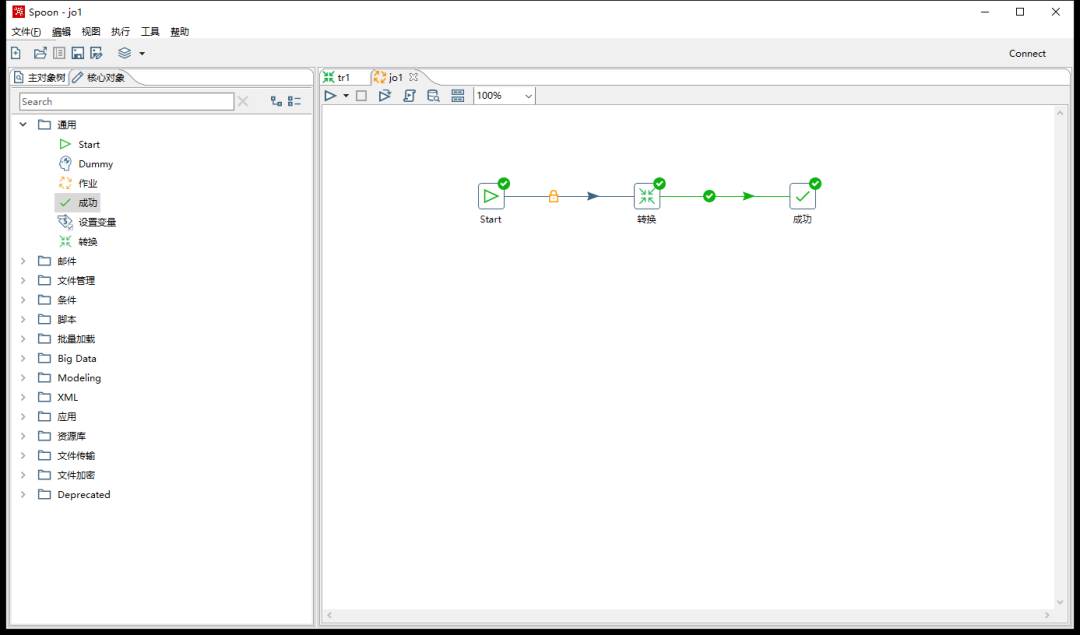
Start
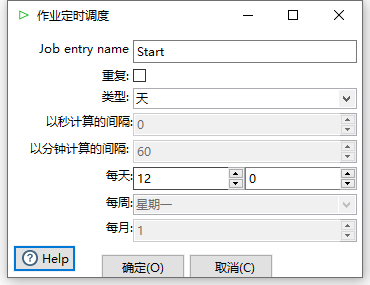
双击Start编辑,可见,可以编辑作业定时执行时间;
转换
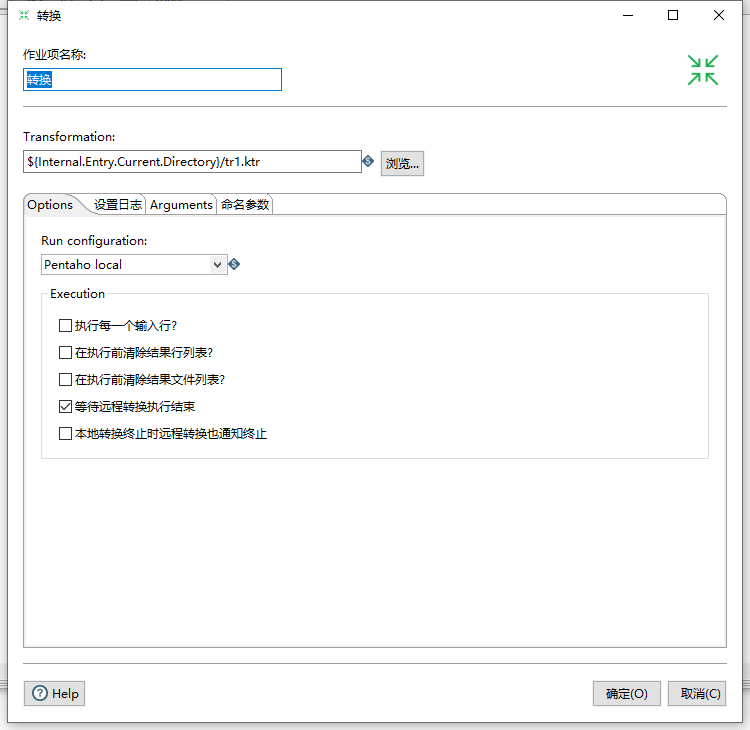
双击转换,选择转换文件,即创建转换保存的ktr文件;
成功
该步骤无内容;
测试
同样的可以在执行结果中查看日志和度量;
从Pan开始 认识后台调度Transform
通过Pan实现后台自动调度Transform;
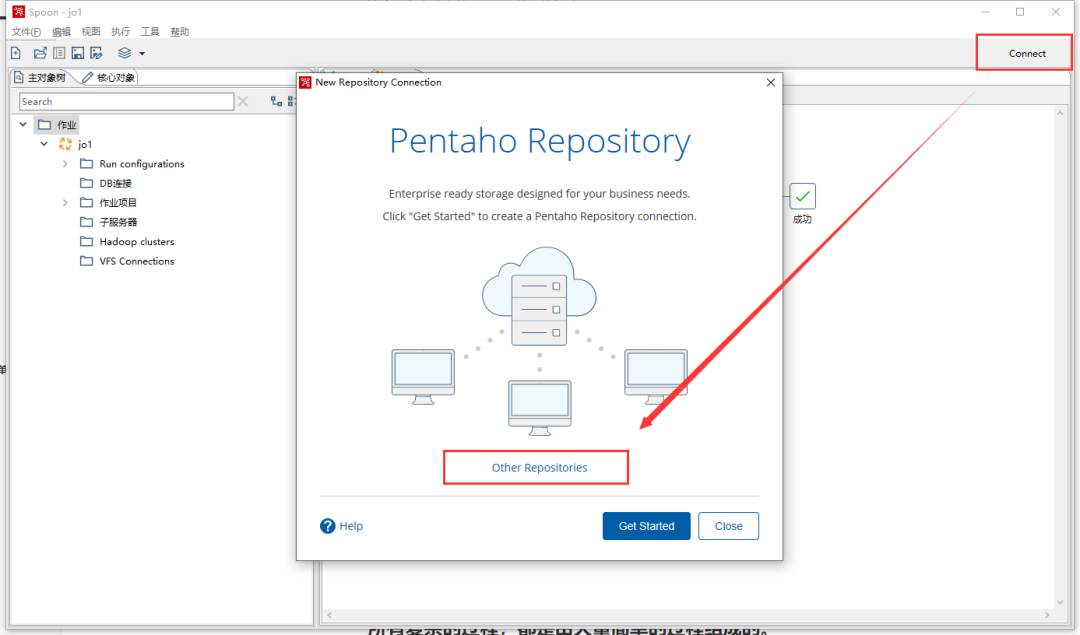
创建资源库
在启动之前需要配置连接资源库,这里我们创建本地资源库:
选择资源库的类型,可选的是数据库类型和文件类型,数据库类型会提示配置数据库连接,这里我们选择文件类型:
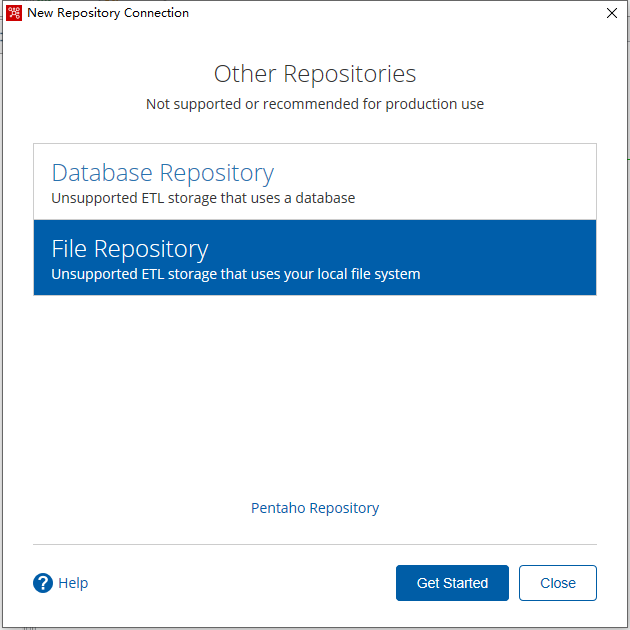
填写资源库名称,选择目录:
Finish:
资源库已创建,可以点击Connect Now连接或者在主界面点击connect连接。
在资源库中创建Transform
资源库可以理解为工作台,你的所有Transform、Job都应当在资源库中创建(也就是在资源库的文件夹下面),先前我们创建的一个Transform和一个Job都不在资源库中,没有关系,我们可以拖动到主界面打开,重新保存到资源库即可;
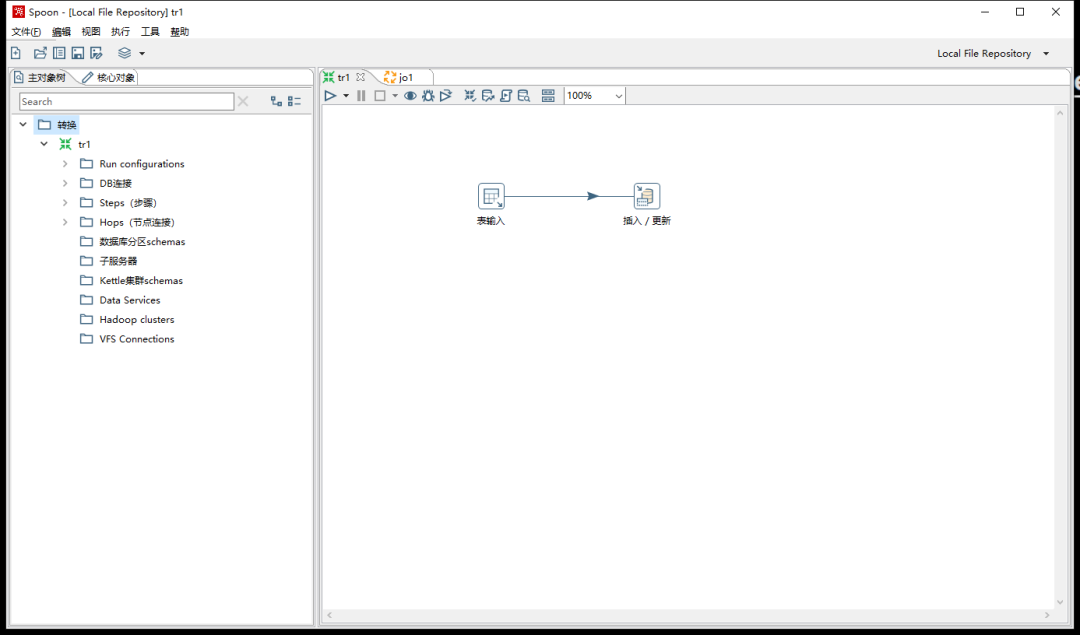
Pan调度Transform
命令行运行kettle文件夹下的Pan.bat(linux环境下为Pan.sh)启动;
Windows下按住Shift+右击,可以在文件夹中快速打开命令行(在此处打开CMD、Powershell等)。
命令行输入:
.\Pan.bat /rep="Local File Repository" /trans:tr1