从示例开始:
创建表:
create table tmp_xml(xml xmltype);填入值:
<?xml version="1.0" encoding="UTF-8" ?>
<collection xmlns="">
<record>
<title>A</title>
<datafield tag="A1" ind1="1" ind2=" ">
<subfield code="a">a1a</subfield>
<subfield code="f">a1f</subfield>
</datafield>
<datafield tag="A2" ind1=" " ind2=" ">
<subfield code="a">a2a</subfield>
<subfield code="b">a2b</subfield>
<subfield code="c">a2c</subfield>
<subfield code="d">a2d</subfield>
</datafield>
<datafield tag="A3" ind1="0" ind2=" ">
<subfield code="a">a3a</subfield>
<subfield code="b">a3b</subfield>
</datafield>
</record>
</collection>查询:
--返回一个节点的一个值,如果对象不是子节点会报错
select extractvalue(xml, '/collection/record/title') as data1
from tmp_xml;
--A
--返回节点下的所有值,返回的xml格式
select extract(xml, '/collection/record') as data
from tmp_xml;
--<?xml version="1.0" encoding="UTF-8" ?><title>A</title>...</datafield>
--检索所有节点值
select extractValue(value(i),'/subfield') data
from tmp_xml,
table(XMLSequence(extract(xml,'/collection/record/datafield/subfield'))) i;
--a1a
--a1f
--...
--a3b
--检索出特定的节点的特定值
select extractvalue(xml, '/collection/record/datafield[@tag="A2"]/subfield[@code="d"]') as data
from tmp_xml;
--a2dOracle 存放 xml 的类型不是只有 xmltype,也包括字符串和 clob,查询方法类似。
以上的例子差不多够了,下面搬一下官方文档的介绍:
原创不够,文档来凑。
Oracle 官方文档:
https://docs.oracle.com/en/database/oracle/oracle-database/index.html
官网关于 extract 的描述:
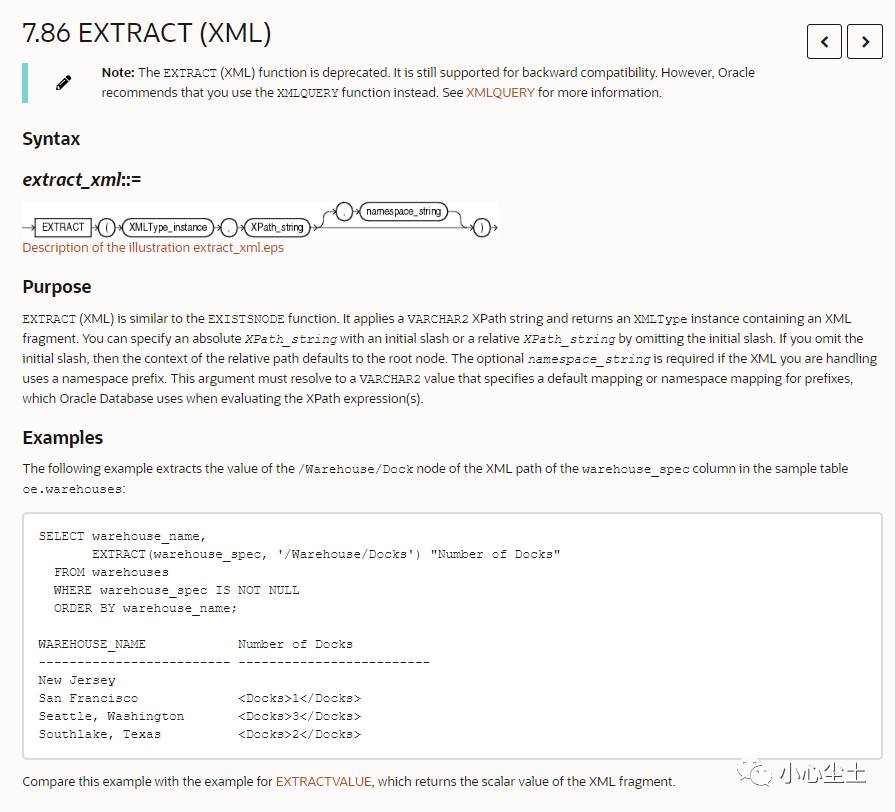
翻译:
<span>EXTRACT</span>
(XML)与<span>EXISTSNODE</span>
功能相似。它应用<span>VARCHAR2 </span>
XPath字符串并返回一个<span>XMLType</span>
包含XML片段的实例。您可以指定XPath_string
带有初始斜杠的绝对值,也可以XPath_string
通过省略初始斜杠来指定相对值。如果省略初始斜杠,则相对路径的上下文默认为根节点。namespace_string
如果您要处理的XML使用名称空间前缀,则为可选。此参数必须解析为<span>VARCHAR2</span>
为前缀指定默认映射或名称空间映射的值,Oracle数据库在评估XPath表达式时使用该值。
例子:
SELECT warehouse_name,
EXTRACT(warehouse_spec, '/Warehouse/Docks') "Number of Docks"
FROM warehouses
WHERE warehouse_spec IS NOT NULL
ORDER BY warehouse_name;
WAREHOUSE_NAME Number of Docks
------------------------- -------------------------
New Jersey
San Francisco <Docks>1</Docks>
Seattle, Washington <Docks>3</Docks>
Southlake, Texas <Docks>2</Docks>官网关于 extractvalue 的描述
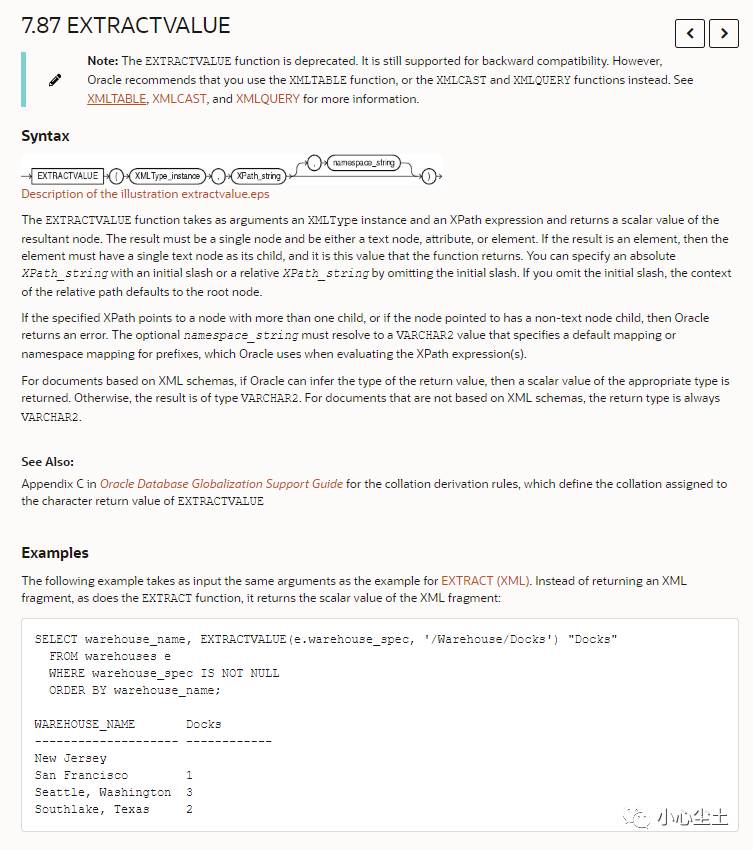
翻译:
该<span>EXTRACTVALUE</span>
函数将<span>XMLType</span>
实例和XPath表达式作为参数,并返回结果节点的标量值。结果必须是单个节点,并且可以是文本节点,属性或元素。如果结果是一个元素,则该元素必须具有单个文本节点作为其子元素,函数返回的就是该值。您可以指定XPath_string
带有初始斜杠的绝对值,也可以XPath_string
通过省略初始斜杠来指定相对值。如果省略初始斜杠,则相对路径的上下文默认为根节点。
如果指定的XPath指向具有多个子节点的节点,或者所指向的节点具有非文本节点子节点,则Oracle返回错误。可选的namespace_string
必须解析为<span>VARCHAR2</span>
为前缀指定默认映射或名称空间映射的值,Oracle在评估XPath表达式时使用该值。
对于基于XML模式的文档,如果Oracle可以推断返回值的类型,则将返回适当类型的标量值。否则,结果为类型<span>VARCHAR2</span>
。对于不基于XML模式的文档,返回类型始终为<span>VARCHAR2</span>
。
例子:
SELECT warehouse_name, EXTRACTVALUE(e.warehouse_spec, '/Warehouse/Docks') "Docks"
FROM warehouses e
WHERE warehouse_spec IS NOT NULL
ORDER BY warehouse_name;
WAREHOUSE_NAME Docks
-------------------- ------------
New Jersey
San Francisco 1
Seattle, Washington 3
Southlake, Texas 2上节讲到 extract 和 extractvalue 提取 xml 数据,用于查询语句,实际上,两者均在 20c 版本已经弃用(仅支持向下兼容),推荐使用 XMLQUERY、XMLTABLE 等。后来重新翻看官方文档,官方给出了完整的关于 XML 的教程,包括存储、生成、访问、搜索、验证、转换、索引等:
https://docs.oracle.com/en/database/oracle/oracle-database/20/adxdb/index.html
同样以上一节的 tmp_xml 数据做示例:
<?xml version="1.0" encoding="UTF-8" ?>
<collection xmlns="">
<record>
<title>A</title>
<datafield tag="A1" ind1="1" ind2=" ">
<subfield code="a">a1a</subfield>
<subfield code="f">a1f</subfield>
</datafield>
<datafield tag="A2" ind1=" " ind2=" ">
<subfield code="a">a2a</subfield>
<subfield code="b">a2b</subfield>
<subfield code="c">a2c</subfield>
<subfield code="d">a2d</subfield>
</datafield>
<datafield tag="A3" ind1="0" ind2=" ">
<subfield code="a">a3a</subfield>
<subfield code="b">a3b</subfield>
</datafield>
</record>
</collection>查询:
XMLQUERY
查询节点的值,可选 where 子句,可选 if 子句:
简单查询:
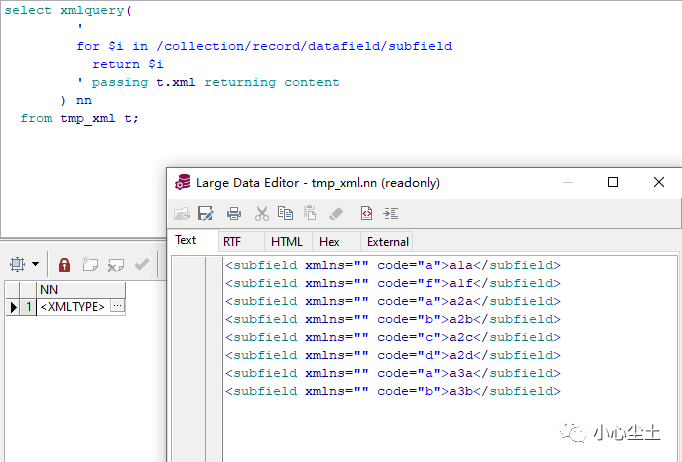
where 子句:
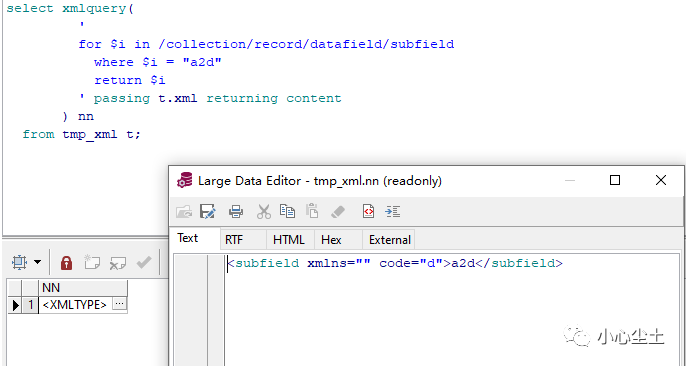
if 子句:
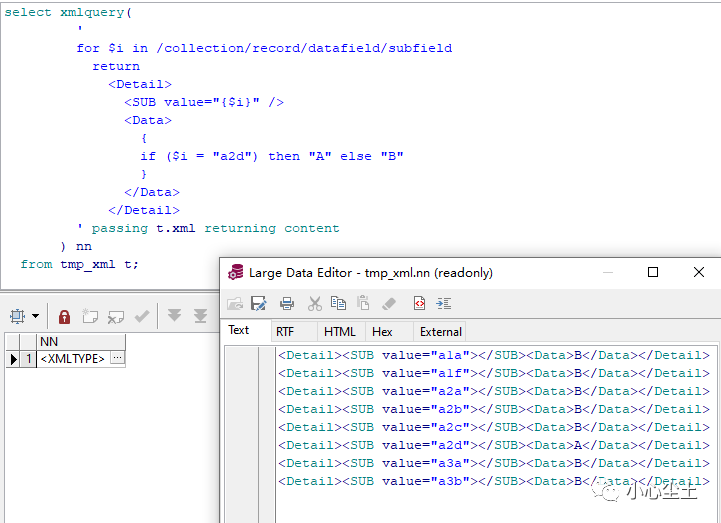
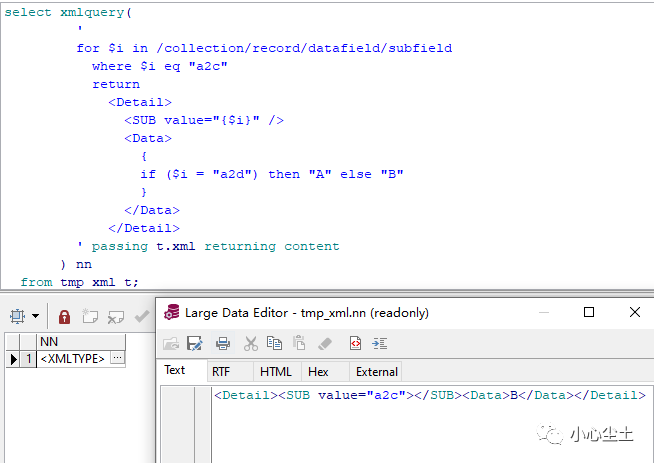
需要说一下的是,where 和 if 子句支持类似 knex.js 的关键字:
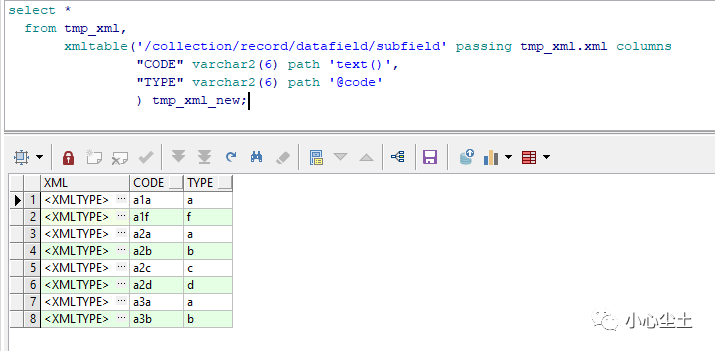
XMLTABLE
返回的表格,要注意的是,path 下的子节点名称需要不一样,但是可以使用 text() 读取值,@code 读取节点的属性 code:
path
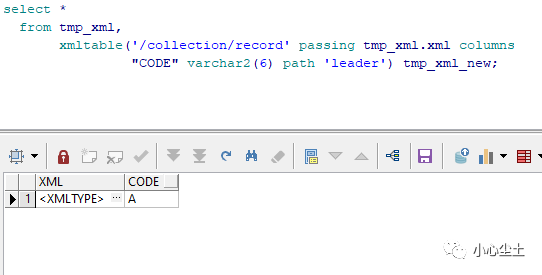
text() @
END
上述只是简单的例举了 XMLQUERY 和 XMLTABLE 的部分例子,实际上关于 XML 的方法还有:(本章开头有链接)
实际上,上述也只是 Functions 部分,就是函数方法部分,在条件部分也有关于 XML 的提取方法: