请注意,本文编写于 914 天前,最后修改于 914 天前,其中某些信息可能已经过时。
从示例开始,准备数据 :
递归结构:
0
├─ 1
│ ├─ 1_1
│ ├─ 1_2
│ └─ 1_3
├─ 2
│ ├─ 2_1
│ │ ├─ 2_1_1
│ │ ├─ 2_1_2
│ │ └─ 2_1_3
│ ├─ 2_2
│ │ ├─ 2_2_1
│ │ │ ├─ 2_2_1_1
│ │ │ ├─ 2_2_1_2
│ │ │ └─ 2_2_1_3
│ │ ├─ 2_2_2
│ │ │ ├─ 2_2_2_1
│ │ │ ├─ 2_2_2_2
│ │ │ └─ 2_2_2_3
│ │ │ │ └─ 2_2_2_3_1
│ │ └─ 2_2_3
│ └─ 2_3
│ ├─ 2_3_1
│ ├─ 2_3_2
│ └─ 2_3_3
└─ 3创建表:
create table tmp_pror(id varchar2(10), p_id varchar2(10));插入数据:
insert into tmp_pror(id, pid) values('0', null);
insert into tmp_pror(id, pid) values('1', '0');
insert into tmp_pror(id, pid) values('1_1', '1');
insert into tmp_pror(id, pid) values('1_2', '1');
insert into tmp_pror(id, pid) values('1_3', '1');
insert into tmp_pror(id, pid) values('2', '0');
insert into tmp_pror(id, pid) values('2_1', '2');
insert into tmp_pror(id, pid) values('2_1_1', '2_1');
insert into tmp_pror(id, pid) values('2_1_2', '2_1');
insert into tmp_pror(id, pid) values('2_1_3', '2_1');
insert into tmp_pror(id, pid) values('2_2', '2');
insert into tmp_pror(id, pid) values('2_2_1', '2_1');
insert into tmp_pror(id, pid) values('2_2_1_1', '2_2_1');
insert into tmp_pror(id, pid) values('2_2_1_2', '2_2_1');
insert into tmp_pror(id, pid) values('2_2_1_3', '2_2_1');
insert into tmp_pror(id, pid) values('2_2_2', '2_1');
insert into tmp_pror(id, pid) values('2_2_2_1', '2_2_2');
insert into tmp_pror(id, pid) values('2_2_2_2', '2_2_2');
insert into tmp_pror(id, pid) values('2_2_2_3', '2_2_2');
insert into tmp_pror(id, pid) values('2_2_2_3_1', '2_2_2_3');
insert into tmp_pror(id, pid) values('2_2_3', '2_1');
insert into tmp_pror(id, pid) values('2_3', '2');
insert into tmp_pror(id, pid) values('2_3_1', '2_1');
insert into tmp_pror(id, pid) values('2_3_2', '2_1');
insert into tmp_pror(id, pid) values('2_3_3', '2_1');
insert into tmp_pror(id, pid) values('3', '0');
commit;数据:
SQL> select * from tmp_pror t;
ID PID
---------- ----------
0
1 0
1_1 1
1_2 1
1_3 1
2 0
2_1 2
2_1_1 2_1
2_1_2 2_1
2_1_3 2_1
2_2 2
2_2_1 2_1
2_2_1_1 2_2_1
2_2_1_2 2_2_1
2_2_1_3 2_2_1
2_2_2 2_1
2_2_2_1 2_2_2
2_2_2_2 2_2_2
2_2_2_3 2_2_2
2_2_2_3_1 2_2_2_3
2_2_3 2_1
2_3 2
2_3_1 2_1
2_3_2 2_1
2_3_3 2_1
3 0
26 rows selected
SQL>数据表只有两个字段,分别为 ID 和父级 PID,但是存储的是整个多层的二叉树,假如我们需要查询一个节点下的所有子节点 :(实际应用为一个公司下各级所有的员工)
SQL> select t.id
2 from tmp_pror t
3 start with t.id = '2'
4 connect by nocycle prior t.id = t.pid;
ID
----------
2
2_1
2_1_1
2_1_2
2_1_3
2_2_1
2_2_1_1
2_2_1_2
2_2_1_3
2_2_2
2_2_2_1
2_2_2_2
2_2_2_3
2_2_2_3_1
2_2_3
2_3_1
2_3_2
2_3_3
2_2
2_3
20 rows selected
SQL>上述查询的结果为节点 2 及以下所有节点。
每个节点可以添加自身属性(表行添加字段),便可以查询所有子节点等。
语句添加在 where 条件之后
start with:起始节点
nocycle:是否循环
order by:排序
以上是一个简单的例子,用法用到 start with connect by,这样的语法还有很多更神奇的用法,包括 level 等。
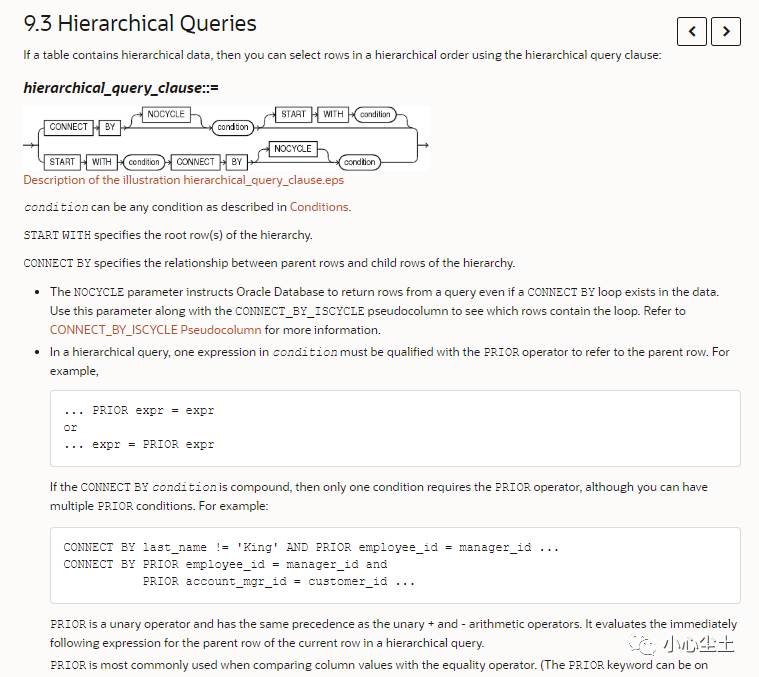
下面搬一下官方文档的介绍:
Oracle 官方文档:
https://docs.oracle.com/en/database/oracle/oracle-database/index.html
Oracle 官方关于本章的文档:
文档很详细,建议多看看官方描述并尝试。这里摘录基本的介绍。