Oracle 正则表达式主要有那么几种(基于 Oracle 20c):REGEXP_LIKE、REGEXP_COUNT、REGXP_INSTR、REGXP_SUBSTR、REGXP_REPLACE。
先上语法结构图(后上代码示例):
REGEXP_LIKE:

REGEXP_COUNT :

REGEXP_INSTR :
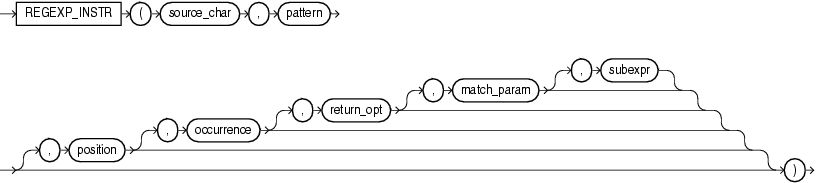
REGEXP_SUBSTR :
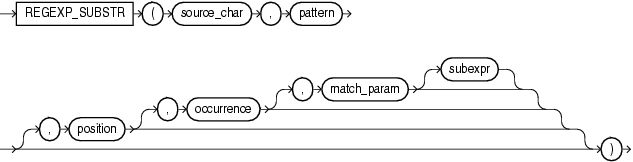
REGEXP_REPLACE:
图片来自于我最喜欢的 Oracle 官方文档:
常用参数说明
source_char:目标字符串、长字符串
pattern:正则表达式
position:检索开始位置,默认第一个字符
occurrence:检索的第几个结果,默认为1,替换时默认全部替换
replace_string:替换的字符串、长字符串
还是来看例子吧:
REGEXP_LIKE**:
REGEXP_LIKE,作为条件表达式(建议先熟悉一下模糊匹配~ ):
where regexp_like(empno,'^[0-9]$')REGEXP_SUBSTR:
SELECT
REGEXP_SUBSTR('500 Oracle Parkway, Redwood Shores, CA',
',[^,]+,') "REGEXPR_SUBSTR"
FROM DUAL;
REGEXPR_SUBSTR
-----------------
, Redwood Shores,这是个官网的例子,解析一下,“'500 Oracle Parkway, Redwood Shores, CA'”是需要解析的字段,“',1+,'”是解析的规则,查询符合规则的字符串,其中“1+”是正则表达式的规则,结合前后的两个“,”表示两个“,”开头结尾的一个任意字符串,“+”理解为任意个。
再上几个例子:
SELECT
REGEXP_SUBSTR('http://www.example.com/products',
'http://([[:alnum:]]+\.?){3,4}/?') "REGEXP_SUBSTR"
FROM DUAL;
REGEXP_SUBSTR
----------------------
http://www.example.com/这个例子,先找出“http://”,然后寻找字谜或者点,寻找三到四次,最后以“/”结尾。
SELECT REGEXP_SUBSTR('1234567890', '(123)(4(56)(78))', 1, 1, 'i', 1)
"REGEXP_SUBSTR" FROM DUAL;
REGEXP_SUBSTR
-------------------
123这里的表达式不止一个,返回第一个表达式“123”的结果。
SELECT REGEXP_SUBSTR('1234567890', '(123)(4(56)(78))', 1, 1, 'i', 4)
"REGEXP_SUBSTR" FROM DUAL;
REGEXP_SUBSTR
-------------------
78返回第四个表达式“78”的结果。
--CREATE TABLE regexp_temp(empName varchar2(20), emailID varchar2(20));
--INSERT INTO regexp_temp (empName, emailID) VALUES ('John Doe', 'johndoe@example.com');
--INSERT INTO regexp_temp (empName, emailID) VALUES ('Jane Doe', 'janedoe');
--COMMIT;
--1
SELECT empName, REGEXP_SUBSTR(emailID, '[[:alnum:]]+\@[[:alnum:]]+\.[[:alnum:]]+') "Valid Email" FROM regexp_temp;
EMPNAME Valid Email
-------- -------------------
John Doe johndoe@example.com
Jane Doe
--2
SELECT empName, REGEXP_SUBSTR(emailID, '[[:alnum:]]+\@[[:alnum:]]+\.[[:alnum:]]+') "Valid Email", REGEXP_INSTR(emailID, '\w+@\w+(\.\w+)+') "FIELD_WITH_VALID_EMAIL" FROM regexp_temp;
EMPNAME Valid Email FIELD_WITH_VALID_EMAIL
-------- ------------------- ----------------------
John Doe johndoe@example.com 1
Jane Doe上述查询为邮箱的检测,大同小异。
with strings as (
select 'ABC123' str from dual union all
select 'A1B2C3' str from dual union all
select '123ABC' str from dual union all
select '1A2B3C' str from dual
)
select regexp_substr(str, '[0-9]') First_Occurrence_of_Number,
regexp_substr(str, '[0-9].*') Num_Followed_by_String,
regexp_substr(str, '[A-Z][0-9]') Letter_Followed_by_String
from strings;
FIRST_OCCURRENCE_OF_NUMB NUM_FOLLOWED_BY_STRING LETTER_FOLLOWED_BY_STRIN
------------------------ ------------------------ ------------------------
1 123 C1
1 1B2C3 A1
1 123ABC
1 1A2B3C A2with 语句。
with strings as (
select 'LHRJFK/010315/JOHNDOE' str from dual union all
select 'CDGLAX/050515/JANEDOE' str from dual union all
select 'LAXCDG/220515/JOHNDOE' str from dual union all
select 'SFOJFK/010615/JANEDOE' str from dual
)
SELECT regexp_substr(str, '[A-Z]{6}') String_of_6_characters,
regexp_substr(str, '[0-9]+') First_Matching_Numbers,
regexp_substr(str, '[A-Z].*$') Letter_by_other_characters,
regexp_substr(str, '/[A-Z].*$') Slash_letter_and_characters
FROM strings;
STRING_OF_6_CHARACTERS FIRST_MATCHING_NUMBERS LETTER_BY_OTHER_CHARACTERS SLASH_LETTER_AND_CHARACTERS
---------------------- ---------------------- -------------------------- ---------------------------
LHRJFK 010315 LHRJFK/010315/JOHNDOE JOHNDOE
CDGLAX 050515 CDGLAX/050515/JANEDOE JANEDOE
LAXCDG 220515 LAXCDG/220515/JOHNDOE JOHNDOE
SFOJFK 010615 SFOJFK/010615/JANEDOE JANEDOE上述语句是一个提取乘客姓名和航班信息的示例。
上述多个示例例举了 REGEXP_SUBSTR 的用法,其余包括 REGEXP_INSTR、REGEXP_REPLACE 等 的用法大同小异:
SELECT
REGEXP_INSTR('500 Oracle Parkway, Redwood Shores, CA',
'[^ ]+', 1, 6) "REGEXP_INSTR"
FROM DUAL;
REGEXP_INSTR
------------
37第六次空格的位置。
SELECT
REGEXP_REPLACE('500 Oracle Parkway, Redwood Shores, CA',
'( ){2,}', ' ') "REGEXP_REPLACE"
FROM DUAL;
REGEXP_REPLACE
--------------------------------------
500 Oracle Parkway, Redwood Shores, CA替换两个以上的空格为一个空格。
正则表达式规则( 多次尝试,更多知识) :
| 值 | 描述 | |
|---|---|---|
| ^ | 匹配一个字符串的开始。如果与“m” 的match_parameter一起使用,则匹配表达式中任何位置的行的开头。 | |
| $ | 匹配字符串的结尾。如果与“m” 的match_parameter一起使用,则匹配表达式中任何位置的行的末尾。 | |
| * | 匹配零个或多个。 | |
| + | 匹配一个或多个出现。 | |
| ? | 匹配零次或一次出现。 | |
| 。 | 匹配任何字符,除了空。 | |
| 用“OR”来指定多个选项。 | ||
| [] | 用于指定一个匹配列表,您尝试匹配列表中的任何一个字符。 | |
| [^] | 用于指定一个不匹配的列表,您尝试匹配除列表中的字符以外的任何字符。 | |
| () | 用于将表达式分组为一个子表达式。 | |
| {M} | 匹配m次。 | |
| {M,} | 至少匹配m次。 | |
| {M,N} | 至少匹配m次,但不多于n次。 | |
| \ n | n是1到9之间的数字。在遇到\ n之前匹配在()内找到的第n个子表达式。 | |
| [..] | 匹配一个可以多于一个字符的整理元素。 | |
| [:] | 匹配字符类。 | |
| [==] | 匹配等价类。 | |
| \ d | 匹配一个数字字符。 | |
| \ D | 匹配一个非数字字符。 | |
| \ w | 匹配包括下划线的任何单词字符。 | |
| \ W | 匹配任何非单词字符。 | |
| \ s | 匹配任何空白字符,包括空格,制表符,换页符等等。 | |
| \ S | 匹配任何非空白字符。 | |
| \A | 在换行符之前匹配字符串的开头或匹配字符串的末尾。 | |
| \Z | 匹配字符串的末尾。 | |
| *? | 匹配前面的模式零次或多次发生。 | |
| +? | 匹配前面的模式一个或多个事件。 | |
| ?? | 匹配前面的模式零次或一次出现。 | |
| {N}? | 匹配前面的模式n次。 | |
| {N,}? | 匹配前面的模式至少n次。 | |
| {N,M}? | 匹配前面的模式至少n次,但不超过m次。 |
更多:

- , ↩
